

TensorFlowのチュートリアルは進んでいますか?
MNISTデータの学習プログラムをいくつか試したら、次は何をすればいいかしら?と思っていませんか?
次は、言語系のチュートリアルに挑戦してみましょう。
ということで、今回は、RNN(Recurrent Neural Networks:再帰型ニューラルネットワーク)を利用したプログラムを動作させてみます。
RNNとは
RNNは、時系列データと呼ばれるデータを扱うニューラルネットワークです。
時系列データとは、あるデータとその次のデータに関連があるデータのことです。
たとえば、音声の波形が時系列データです。
2箇所で同じ周波数であったとしても、前後の周波数によって「あ」に聞こえたり「い」に聞こえたりするため、前後のデータを含めて学習する必要があるのです。
その他にも、日本語とか英語のような自然言語も時系列データです。
「はしをもつ」の「はし(箸)」と、「はしをわたる」の「橋/端」は、「はし」は同じ文字ですが、前後にある文字で意味がまったく変わってしまいます。
これもやはり時系列データと言えそうですね。
RNNは、このようなデータを学習するときに有用なモデルとして考案されました。
LSTM
RNNの一種であるLSTM(Long short-term memory)というモデルも注目されています。
LSTMは、RNNを拡張したモデルで、RNNにある記憶領域をパワーアップさせたものと考えてください。
LSTMの特徴は、RNNでは学習できなかった(時系列データとして)遠くにあるデータとの関連を学習できることです。
通常のRNNでも、数10程度遠くにあるデータとの関連は学習できますが、それ以上は難しくなります。
一方、LSTMであれば、1000程度遠くにあるデータとの関連も十分に学習できるのです。
Bidirectional RNN
Bidirectional RNNというモデルもあります。
RNNは、過去データと現在のデータの関連を学習しますが、Bidirectional RNNは、それに加えて未来のデータと現在のデータの関連(逆方向の関連)も学習します。
Bidirectional RNNが有用なケースとして、簡単な数列を見てみましょう。
1、2、?、4、5と数字が並んでいたときは、「?」は3になるだろうと予測できます。
一方、1、2、?、8、16と並んでいたときは、「?」は4になりそうです。
このように、「?」の前は同じ「1、2」でも、「?」の後が変わることで「?」に入る数字も変わりそうです。
このようなケースでは、RNNやLSTMではなく、Bidirectional RNNを使えば正しく学習することが期待できます。
タスクを確認しよう
TensorFlowのサイトに、「Recurrent Neural Networks」(再帰型ニューラルネットワーク)というページがあります。
参考:https://www.tensorflow.org/tutorials/recurrent
最新のURL:https://www.tensorflow.org/tutorials/sequences/recurrent
ここからは、このチュートリアルを試してみますが、その前に、上記のチュートリアルで扱うデータと、このチュートリアルのゴールを確認しましょう。
学習に使用するデータは、以下のような英文です。
japanese companies have financed small and medium-sized u.s. firms for years but in recent months the pace has taken off
このような英文を約42000文学習した上で、任意の英単語の次にどのような単語が出現するかを予測する(モデルを作成する)のがゴールです。
ここでは、このプログラムを「英単語の予測プログラム」と呼ぶことにしましょう。
RNNの公式チュートリアルに挑戦!
この記事では、チュートリアルの解説はそのページにお任せして、解説されているプログラムを試してみることにします。
プログラムをダウンロードする
まずは、以下のページから、ptb_word_lm.py、reader.py、util.pyをダウンロードします。
参考:https://github.com/tensorflow/models/tree/master/tutorials/rnn/ptb
この3つのファイルを同じフォルダに保存します。
任意のフォルダに保存すれば大丈夫ですので、ここでは「D:\TensorFlow\RNN」フォルダに保存しました。
PTBデータセットをダウンロードする
次に、PTB(Penn Treebank)データセットをダウンロードします。
PTBデータセットは、ウォールストリートジャーナルなどの原稿から作成されたデータセットで、英語での言語処理でよく使われています。
このチュートリアルでは、PTBデータセットのうち、ptb.train.txt、ptb.valid.txt、ptb.test.txtの3つを使います。
この3つのファイルは、実はいろいろなところで配布されており、どこからダウンロードしても大丈夫です。
ここでは、TensorFlowのチュートリアルのとおり、以下のファイルから取り出します。
参考:http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
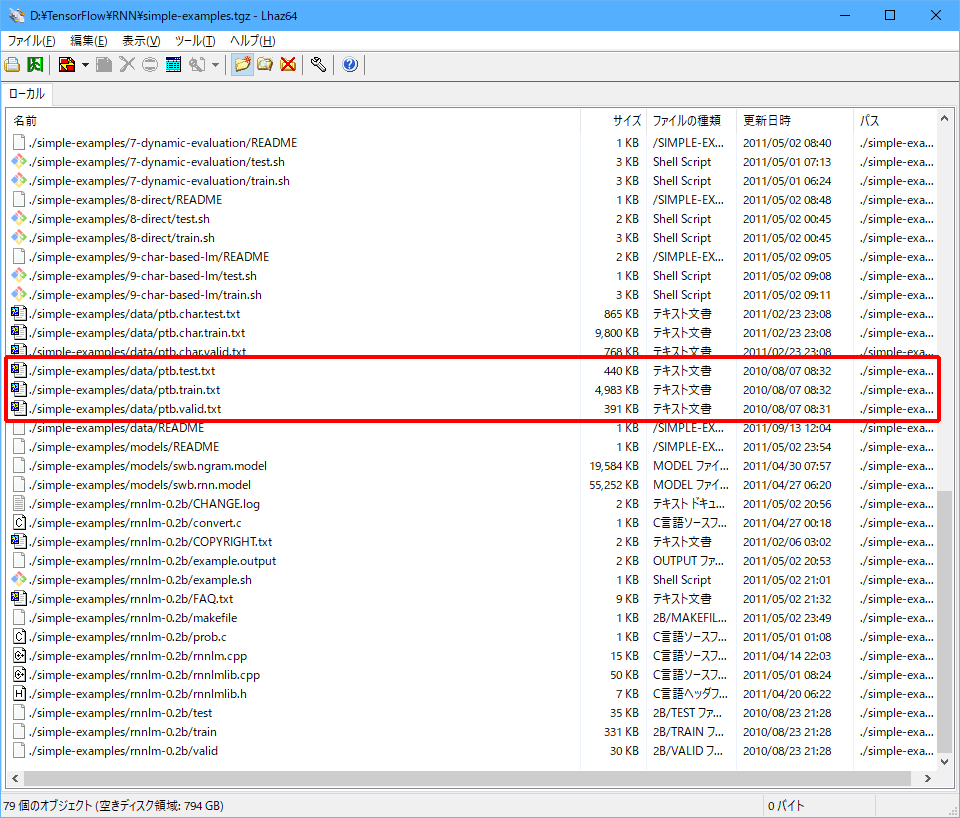
ダウンロードしたsimple-examples.tgz(圧縮ファイル)の内容を確認すると、以下のようにたくさんのファイルが含まれています。
必要なファイルは、赤枠で囲んだptb.train.txt、ptb.valid.txt、ptb.test.txtの3つです。
文章を学習する
プログラムとデータの準備ができたところで、TensorFlowをインストールした環境で機械学習を実行してみましょう。
ここでは、Anaconda NavigatorからGPU版TensorFlowをインストールしたPython環境を起動して、「D:\TensorFlow\RNN」フォルダに保存したptb_word_lm.pyを実行する操作を説明します。
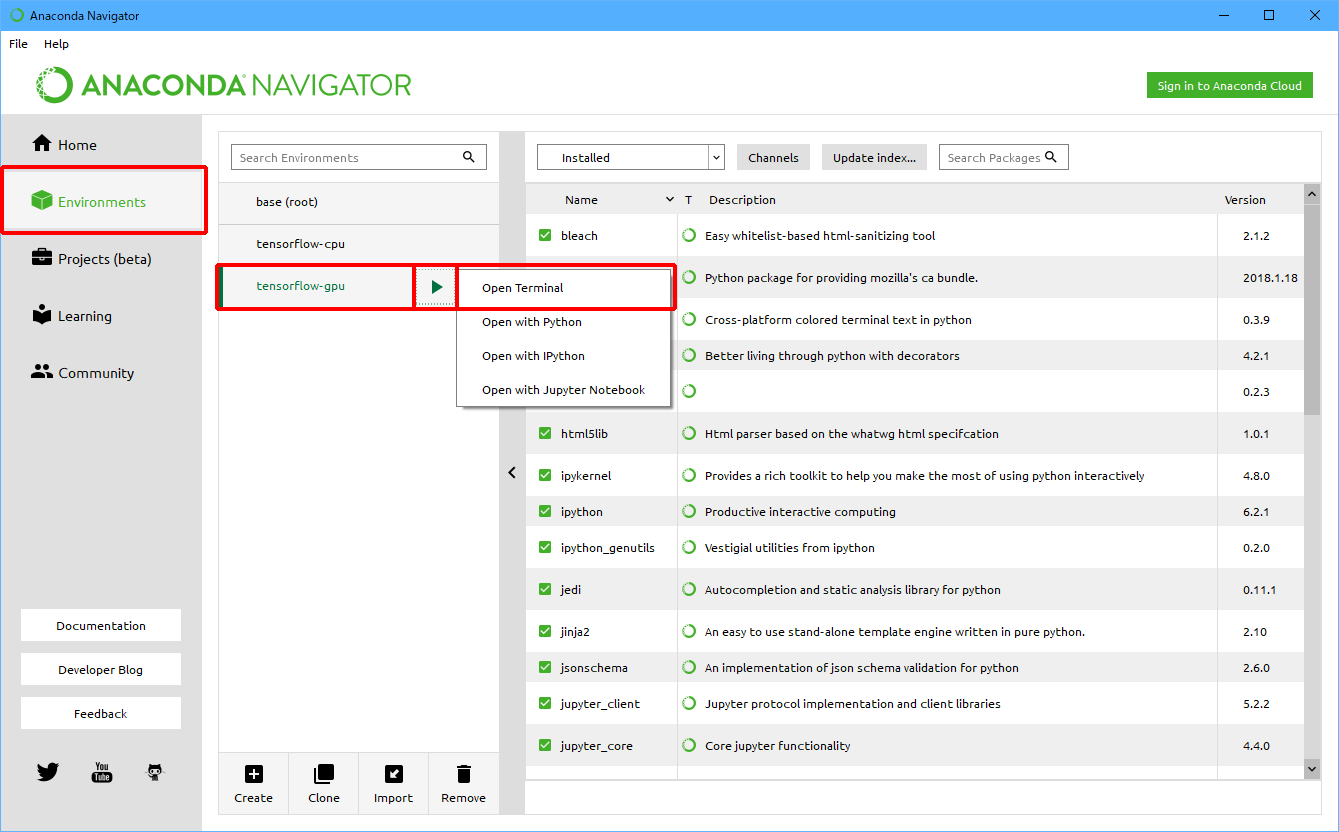
(1)Anaconda Navigatorを起動します。
(2)「Environment」をクリック後、「tensorflow-gpu」をクリックし、「![]() 」をクリックして、「Open Terminal」をクリックします。
」をクリックして、「Open Terminal」をクリックします。
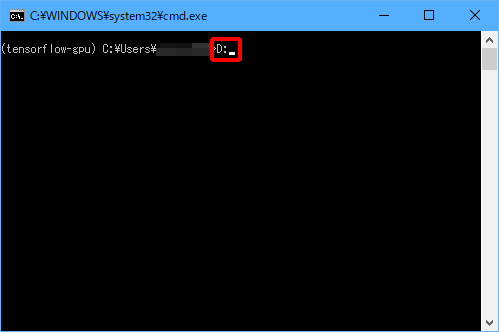
(3)「D:」と入力し、Enterキーを押します。
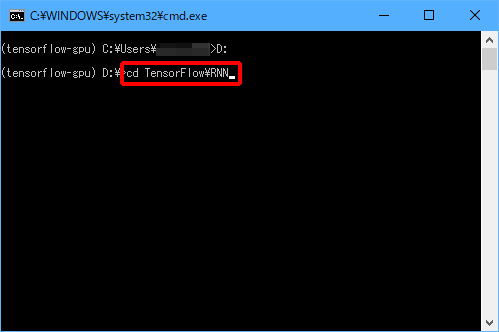
(4)「cd TensorFlow\RNN」と入力し、Enterキーを押します。
(5)「python ptb_word_lm.py –data_path=data –model=small」と入力し、Enterキーを押します。
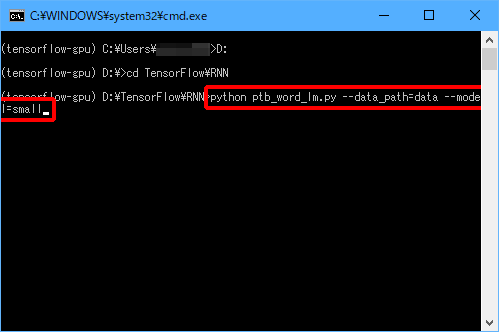
実行中は以下のような画面が表示されます。
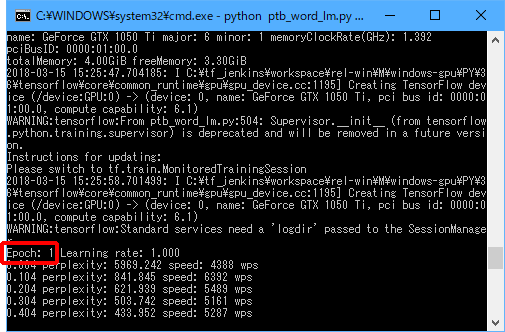
「Epoch: xx」の部分が、13になると終了ですので、終了するまで待ちます。
終了すると、以下のように表示されます。
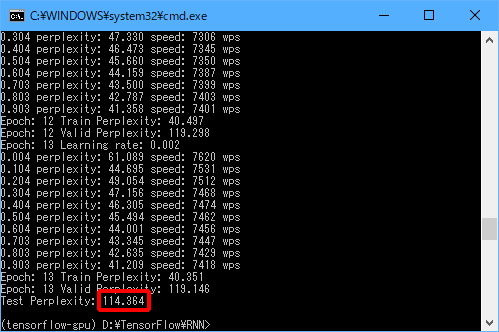
Test Perplexity(≒テストデータの次に来そうな単語の数)に「114.364」と表示されていますので、テストデータでは次に来そうな単語が(無限個ではなく)「114.364」個まで限定できたことがわかりました。
まとめ
今回は、TensorFlowでLSTMを利用して、任意の英単語の次にどのような単語が出現するかを予測するモデルを作成するプログラムを実行してみました。
今回は「–model=small」で実行しましたが、「–model=medium」や「–model=large」で実行することもできます。
「–model=small」以外で実行すると、モデルが大きくなるため学習時間がかかりますが、Perplexityの数は小さくなります。
パラメータをどのように変更しているかは、ptb_word_lm.pyを読めば理解できますので、ぜひ読んでみてくださいね!




