

こんにちは!インストラクターのフクロウです。
機械学習の分類の一つに「クラスタリング」があります。ラベルのつけられていないただのデータから法則を学習して、クラスター(データのまとまり)を自動で見つける方法です。
この記事で
- クラスタリングとは?
- クラスタリングとクラス分類の違いとは?
という基本的な内容を理解しましょう。
そしてその発展として
- クラスタリング手法k-meansをscikit-learnで試す
を行います。機械学習初心者必見! この記事でクラスタリングの仕組みの理解と実装に挑戦しましょう!
クラスタリングとは?

クラスタリング
クラスタリングとは、機械学習の目的別の分類の一つです。教師あり学習では教師データ(ラベルとデータのセットがたくさんあるもの)から、データに対するラベル付の法則性を見つけていました。
これに対して、クラスタリングは教師なし学習です。例えば、以下のようなデータ(このデータはiris datasetの一部です)があるとします。
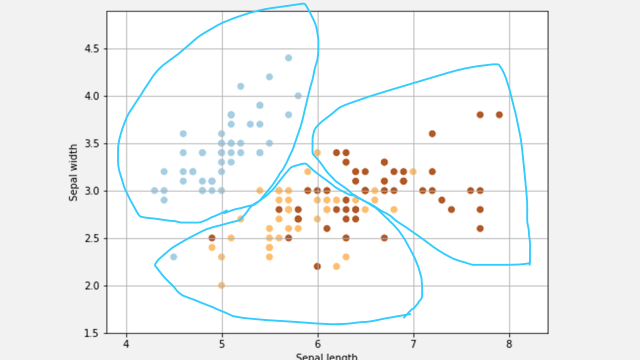
水色の線がクラスタを表していると思ってください。このクラスタはデータから、ラベルを気にせずにそれらしいまとまりをつけてみたものです。
このようにクラスタリングは、ラベルのない”ただのデータ”から、データのクラスター(データのまとまり)をいくつか見つけます。または、ラベルがあるデータだとしても、ラベルを使わずにクラスタをいくつか見つけます。
その結果出てくるクラスタはクラス分類した場合とは異なったデータ構成になっていることが多いです。
クラスタリングとクラス分類
クラスタリングと混同されるものにクラス分類があります。クラス分類は教師あり学習であり、ラベル付けされたデータから法則性を学習して、クラスが未知のデータをクラス分けします。
クラス分類については以下の記事で詳しく解説しています。是非チェックしてください!

クラスタリングの代表的な手法
クラスタリングは様々な機械学習モデルで行うことができますが、有名なところでは
| 名前 | 日本語名 |
| k-means | k平均法 |
| hierarchical clustering | 階層型クラスタリング |
などがシンプルでよく使われます。これらは様々な派生手法があり、クラスタの作り方を変えたりクラスタ数を自動で決めるような手法があります。
k-meansを使ってみる

以下のコードを自分のjupyterlabやjupyter notebookの環境で試してながら読み進めてください。
という方は以下の記事をチェック!

k-meansとは
k-meansはクラスタリングの最もシンプルな実装の一つです。meanとは平均を意味し、クラスタを構成するデータの中で平均点をk個用意(最初はランダムな値で平均点を作ります)します。各データに対して、自分から一番近い平均点を計算します。
一番近い平均点のクラスタが各データの所属するクラスタです。全てのデータのクラスタが決定したら、更にクラスターを構成するデータの中で平均点を作り直します。
そうやって平均点を更新したら、またはじめのように各データの一番近い平均点を見つけて所属クラスタを更新します。このような処理を平均点が更新されなくなるか、ループの上限回数(これは好きに決めてください)に達するまで繰り返します。
実際に使うデータ
クラス分類と同様にiris datasetを使います。さて、まずはどんなデータなのか見てみましょう!
import seaborn as sns
iris = sns.load_dataset("iris")
# ちなみにこのirisはpandasのdataframeです。
iris.head(20)
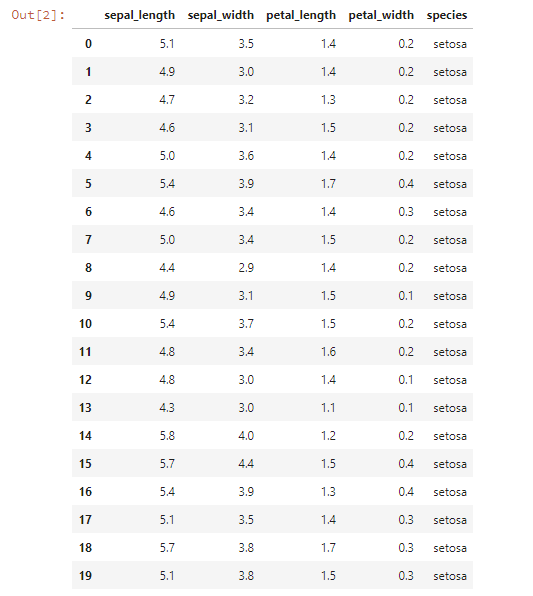
この表では0から19までのデータしか表示されていませんが、実際には150個のデータがあります。
次に、4つある特徴から2つずつ取り出してデータを可視化してみます。
sns.pairplot(iris, hue = "species", diag_kind="kde")
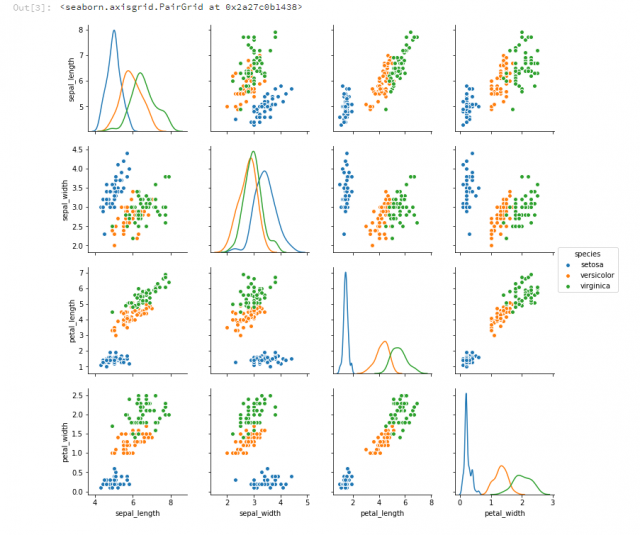
青いクラス(setosa)とそれ以外との分類は簡単そうですね。今回はクラスタリングなので、クラスとは違ったグループ分けが行われるはずです。
k-meansのscikit-learn実装を試す
では実際にk-meansを使ってみましょう。まずはsklearnをimportして、k-meansクラスからirisデータセット向けに設定したインスタンスを作ります。
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3, max_iter=30, init="random", n_jobs=-1)
ここで、KMeansの引数は
- n_clusters: クラスタの数
- max_iter: 学習のループ回数
- inin: 平均の初期値の決め方
- n_jobs: k-meansを何並列にするか(-1ならばpcのコア数分だけ並列してくれます)
のような設定を意味します。これ以外にも引数は用意されているので、更にいじってみたい人は調べてみてください。さて、それでは早速クラスタリングを行います。
cluster = kmeans.fit_predict(iris.values[:,0:4])
ここで、iris.values[:,[0:4]]という記述は、irisというデータフレームの列の0~4番目までを使う、という意味になります。
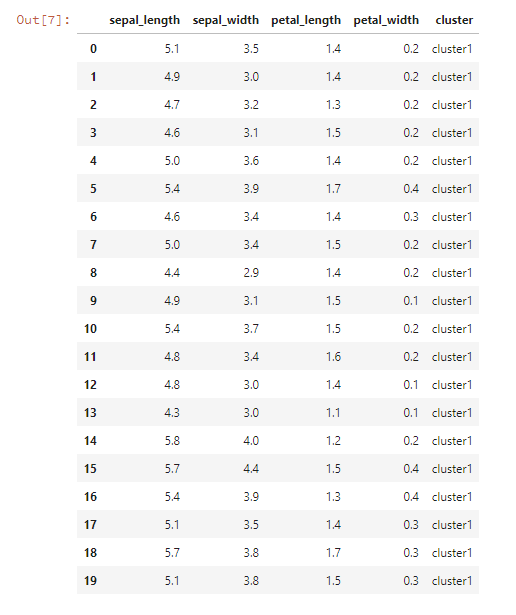
実行結果を見てみましょう。まずは分かりやすいように、データフレームにclusterを追加して、表として表示してみます。
iris2 = iris.iloc[:,[0,1,2,3]] iris2["cluster"] = ["cluster"+str(x) for x in cluster] iris2.head(20)
次に、最初と同じ様にsns.pairplotでclusterを元に色分けしたグラフを表示してみましょう。
sns.pairplot(iris2, hue = "cluster", diag_kind="kde")
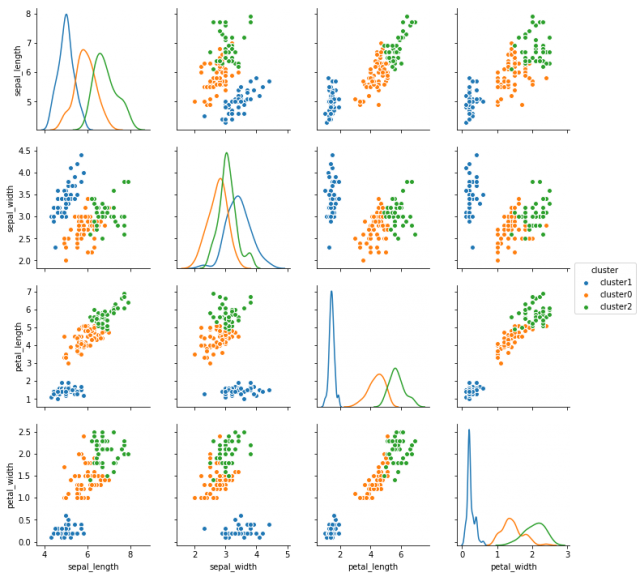
もとのグラフと比べてみると、3つあるデータのまとまりが意外に違うデータでできていることがわかります。k-meansクラスタリングがクラス情報を使わずに、データのまとまりを見つけることができていることがわかりますね。
クラスタリングを更に学ぶには

クラスタリングの方法はここで紹介したk-means以外にもたくさんあります。より高精度の分類を求める場合などは、Deep Learningを使ったものもあります。
教師なし学習は今注目されている分野の一つです。実社会のデータはラベル付けされているものが少なく、少ない教師データで学習するか、ラベルなしで学習することも選択肢に入ります。
このようなクラスタリングや機械学習のレッスンを受けたい!という方には侍エンジニアをおすすめします。侍エンジニアでは、マン・ツー・マンレッスンでこのような機械学習の手法についてレッスンを行っています。
[su_button url=”https://lp.sejuku.net/lp1_blog_01/?cid=ai_btn1_60630″ target=”blank” background=”#409fdf” color=”#fff88f” size=”10″ center=”yes” radius=”10″ icon=”icon: external-link” icon_color=”#fff88f” text_shadow=”0px 0px 10px #808080″]侍エンジニアとは?
詳細はこちらから[/su_button]
もっと機械学習、クラスタリングを学びたい!という方は是非、侍エンジニアでマン・ツー・マンレッスンを受講してみてください!
まとめ
この記事では
- 機械学習によるクラスタリングの解説
- 特にk-meansのPython実装について
解説しました。クラスタリングはビッグデータから有益な知見を得るために重要な技術の一つです。
最も基本的なk-meansアルゴリズムを理解したら、次は更に強力なアルゴリズムに挑戦してみてください!




