

この記事では話題の可視化ライブラリ「seaborn」を紹介します。
データ解析、機械学習ではデータの可視化は非常に重要です。データの全体像がわからないと解析の使用が無いですし、学習の結果を人にうまく伝えるためにもスマートなグラフが必要です。
この記事では、
- seabornとは
- seabornの使い方
についてまとめました。
また、使い方では特に
- pairplot
- jointplot
- clustermap
という関数を重点的に紹介します! この記事でseabornの世界に飛び込みましょう!
seabornとは
seabornはPythonでグラフを作るためのライブラリです。matplotlibで作れるグラフを更にかっこよくしてくれる機能もあり、今までmatplotlibを使っていた人たちにオススメです。
手軽に美しいグラフを描画できる機能が沢山用意されているので、matplotlibで頑張って作っていたようなグラフも、もしかしたらseabornの関数一個でできてしまうかも知れません。インストールは condaかpipから行いましょう。
pip install seaborn conda install seaborn
seabornの使い方

この章ではseabornを使ってグラフを作成していきます! 以下のサンプルコードはすべてJupyter Notebook/Labで動作確認しました。ぜひ実際に試しながら読み進めてください。
seabornでmatplotlibのグラフをかっこよくできる
seabornには様々な便利機能がありますが、それらを覚えなくても簡単にseabornのかっこいいグラフが作れちゃいます。実際にどんなグラフができるか、元のmatplotlibのグラフと比較して見てみましょう。
まずはライブラリのimport。
import seaborn as sns import matplotlib.pyplot as plt import numpy as np
numpyでトイデータを作って簡単なグラフを作ります。
x = np.linspace(1,100) # matplotlibそのままでグラフ作成 plt.plot(x)
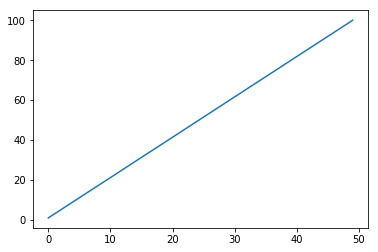
これをseabornパワーでかっこいいグラフにしてみましょう!
# seabornでスタイルを変更 sns.set() plt.plot(x)
重要なのはsns.set()。これだけです。これだけで下のようなグラフになります。
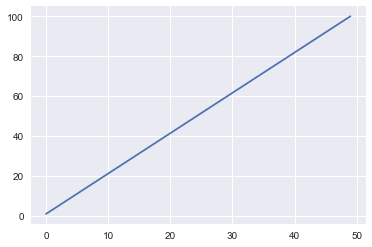
どうですか? かっこよくないですか? matplotlibが既にわかっているなら、seabornのコードを一行追加するだけで活用できます!
seabornでデータセットを読み込む
seabornにはデータセットを読み込む機能があります。これを使って有名なデータセットをpandasのDataFrame形式で使うことができます。
# snsで使えるデータ一覧 sns.get_dataset_names()
[出力結果]
['anscombe', 'attention', 'brain_networks', 'car_crashes', 'dots', 'exercise', 'flights', 'fmri', 'gammas', 'iris', 'planets', 'tips', 'titanic']
irisは言わずもがな、titanicなどは、kaggleでも使われているデータですね。データの読み込みはsns.load_data(“データセット”)の一行でOK。
iris = sns.load_data("iris") # irisを読み込み
data = sns.load_dataset("attention") # attentionを読み込み
iris.head()

便利でかっこいいグラフを作成
読み込んだデータを使い、seabornでグラフを作ってみましょう!
pairplot:全ての変数の組み合わせごとにデータの散布図を作る
seabornといったらpairplot関数! この関数はデータの全ての変数(特徴)を2つずつの組み合わせにして、それぞれの組み合わせで散布図を作ります。
sns.pairplot(iris)
実行コードはこれだけ。pairplot関数の引数はDataFrameにしてください。
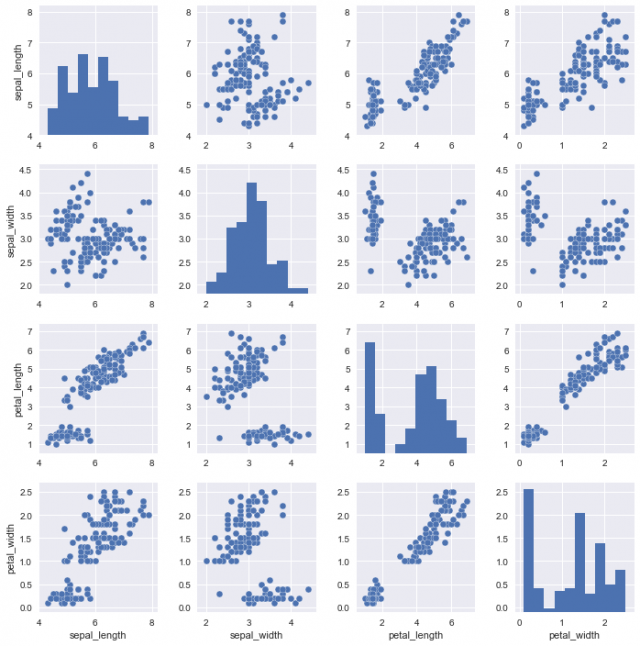
その結果できたグラフがこれです。非常に簡単ですね。
また、クラスごとにデータの色を変えたい場合は、hue引数にクラスに相当するDataFrameのカラムを指定します。
# hueに指定したcolumnを基準にデータを色分け sns.pairplot(iris, hue="species")
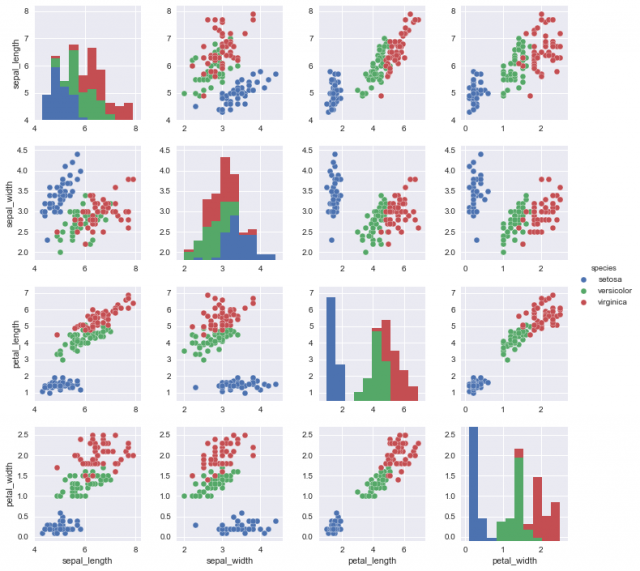
この方が見やすいですね。どのカラムがクラスに相当するのかは、DataFrameをプリントするなどして確認してみてくださいね。
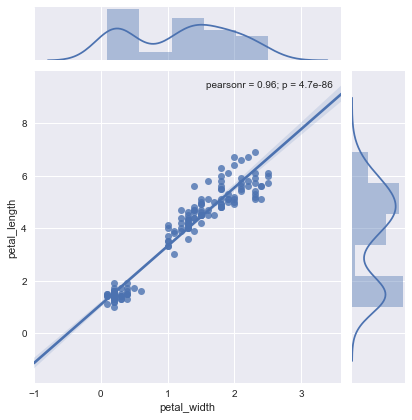
jointplot:特定の特徴の組み合わせの散布図
先程は全ての組み合わせの散布図を一気に出す関数でしたが、一部だけ確認したいことも多いですよね。そんな時はjointplot関数を使います。
sns.jointplot(“x軸に相当するカラム”, “y軸に相当するカラム”, data=データセットのデータフレーム)のようにして使います。
sns.jointplot('sepal_width', 'petal_length', data=iris)
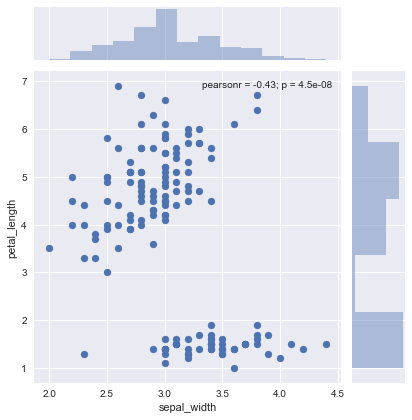
また、散布図の部分はいろいろなグラフで代用できます。kind引数にグラフの名前を指定してあげれば試せるので、やってみましょう。
# 表示を六角形でかっこよく変更
sns.jointplot('sepal_width', 'petal_length', data=iris, kind="hex")
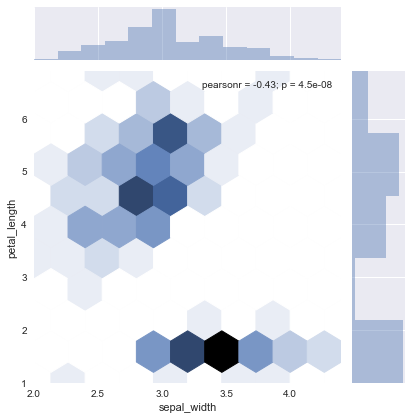
# 等高線で密度を表示
sns.jointplot('petal_width', 'petal_length',data=iris, kind="kde")
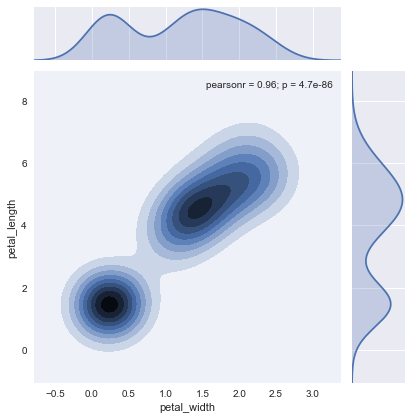
# 線形回帰もできる
sns.jointplot('petal_width', 'petal_length', data=iris, kind="reg")
clustermap:相関関係の可視化とデンドログラムの作成
データの変数同士の相関関係を可視化したり、変数同士の類似度をデンドログラム(階層型クラスタリングで作れるグラフです)で確認したい場合は結構多いです。
こんなときに一回にこれらをやってくれる関数がclustermapです。clustermapの引数には相関行列のデータフレームを渡してあげればOKです。
sns.clustermap(iris.corr())
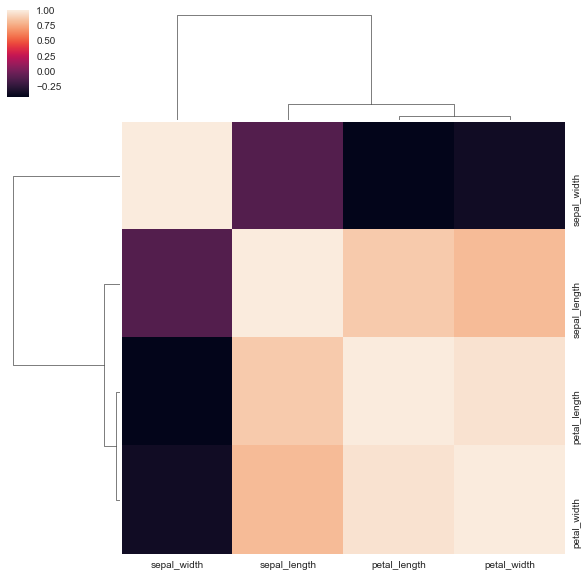
ヒートマップで相関が一目瞭然ですし、デンドログラムも有用性が高そうですね。
もっとデータ可視化について学びたい

データの可視化は機械学習やデータ解析の分野では重要な技術です。
この記事ではseabornというクールな可視化ライブラリを使いましたが、
- 何を可視化すべきなのか
- どう可視化するべきか
などを考えることが重要です。上手いグラフはデータの全体像を把握するのに役に立ちますし、機械学習などを知らない人たちにプレゼンするときにも説得力が出ます。
データ可視化や機械学習について更に詳しく知りたい場合は、侍エンジニアのマン・ツー・マンレッスンがオススメです。生徒さん一人ひとりに対してカリキュラムが作られるので、あなたの興味がある分野を更に深く知ることができます!
[su_button url=”https://lp.sejuku.net/lp1_blog_01/?cid=ai_btn1_61017″ target=”blank” background=”#409fdf” color=”#fff88f” size=”10″ center=”yes” radius=”10″ icon=”icon: external-link” icon_color=”#fff88f” text_shadow=”0px 0px 10px #808080″]侍エンジニアとは?
詳細はこちらから[/su_button]
まとめ
この記事ではPythonの可視化ライブラリseabornを紹介しました。かっこいいグラフを作るならseabornが手軽でオススメです。ぜひ使ってみてください!




