

こんにちは!インストラクターのフクロウです!
Pandasの使い方について、侍ではいくつか記事を公開してきました。




この記事では、DataFrameを使ったデータ操作を学んでいきます。
特に、「pandasによる統計量の計算とデータの前処理」について見ていきますよ。
- DataFrameとは
- DataFrameの基本操作
- DataFrameで統計量の算出
- DataFrameでデータの前処理
などについて紹介します。データ解析をするときにはもうおなじみになったpandasのDataFrame、この期に使いこなしちゃいましょう!
PandasのDataFrameを使ったデータ操作について学ぶことは、データ分析の基礎を築く重要なステップです。しかし、これだけでは未来のキャリアに対する不安を完全には解消できないかもしれません。もし「もっと実践的なスキルを身につけて収入を増やしたい」と感じているなら、他のスキルを組み合わせてみるのも一つの方法です。
AIとWeb制作を組み合わせることで、すぐに使えるノウハウを得られ、収益化の具体的な流れも学べます。この機会を活用すれば、時間や収入、キャリアの面で新しい未来が見えてくるでしょう。セミナーの詳細を見て、自分に合った方法を探してみませんか?
DataFrameとは
DataFrameとは、Pandasの提供するデータ形式の一つです。行、列の名前をもたせることができ、さながらMicrosoft ExcelなどのSpreadsheetのような見た目をしています。
DataFrameの操作
このセクションでは、DataFrameの基本的な操作を確認します。
また、データ解析の際に必要なデータの統計量の計算についても触れていきます。まずはライブラリをimportしましょう!
import pandas as pd import numpy as np from sklearn import datasets from scipy import stats
そしてデータフレームの作成です。
iris = datasets.load_iris() df = pd.DataFrame(iris.data) df["label"] = [iris.target_names[i] for i in iris.target]
DataFrameの基本的な操作
df.shapeでサイズ確認
DataFrameのサイズをまずは確認してみましょう。
df.shape #(150, 5)
numpy.arrayに似ていますね。
先頭要素・末尾要素の取り出し
DataFrameの先頭要素を取り出してみます。
df.head()
[出力結果]
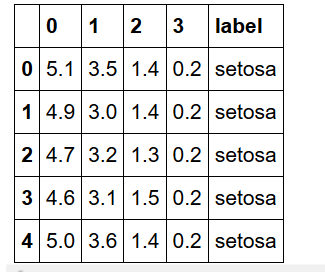
df.head()そのままで使うと、先頭5行を取り出します。df.head(N)のように数字を指定すれば、先頭N行を取り出します。ではその逆で、後ろからN行を取り出す場合です。
df.tail()
[出力結果]
こちらも末尾からN行取り出すには、df.tail(N)とします。
スライス
numpy.arrayやPythonのlistには、スライス記法という物がありました。同じようなことをDataFrameでもやってみましょう。
df[0:5] # スライス
[出力結果]
df[~]とすることで、listのようにスライスできます。
また、行だけでなく、列も含めてスライスしたい場合は、df.ilocを使ってスライスします。カッコの中はnumpy.arrayのスライスと同様です。
df.iloc[:5,:-1] # numpy.arrayのようなスライスもできる
[出力結果]
もちろん、特定の要素を取り出すこともできます。
df.iloc[2,3] # 0.2
統計量
統計量の計算を一発でやってしまいましょう。df.describe()メソッドを使うと、各特徴ごとに以下のような条件を計算したDataFrameを返します。
df.describe()
[出力結果]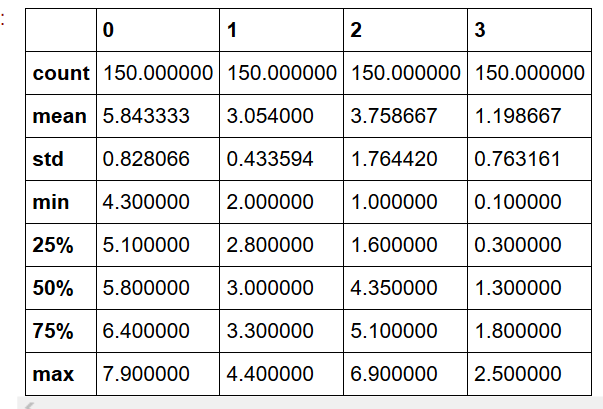
DataFrameでデータの前処理
Deep Learningをするにもscikit-learnに入っているような従来の機械学習をするにも、データの前処理は欠かせません。この前処理、実際にやってみると機械学習のモデルを組むことよりも大変だったりします。
これをDataFrameの機能を使って簡単に終わらせてしまいましょう。
標準化
標準化は、データをN(0,1)になるように変換します。つまり以下の処理を行います。
(x - x_mean) / x_std
さて、scipyの関数を使えば簡単にできてしまうこの標準化、DataFrameと組み合わせて使ってみましょう。DataFrameの各行、あるいは各列に対する処理をするにはdf.applyメソッドを使います。
例:df.apply(関数, axis=適用したい軸)
df2 = df.iloc[:,:-1].apply(stats.zscore, axis=0)
[出力結果]
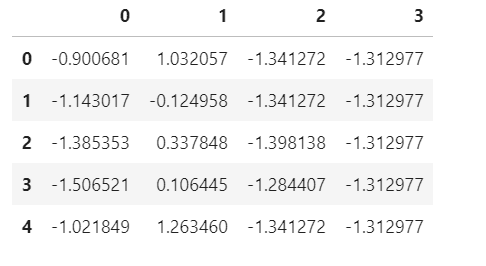
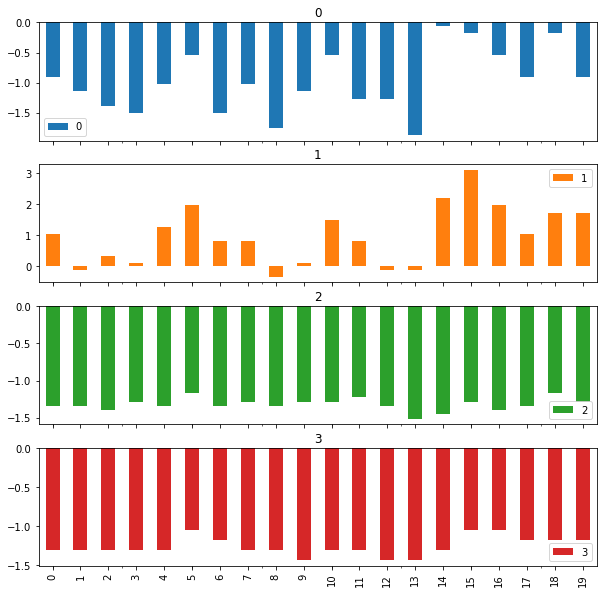
stats.zscoreは標準化を行う関数です。ここで、dfの最後の列にデータラベルが入っているため、標準化を適用しては行けないことに注意して下さい。ちなみにこれを可視化してみると以下のようになります。
df2[:20].plot(kind="bar", subplots=True, figsize=(10,10))
[出力結果]
正規化
正規化は以下の処理のことです。
(x-x_mean)/(x_max - x_min)
さて、この関数もSciPyにあればよかったのですが、見つけられませんでした。ではこの関数を、DataFrameのメソッドを組み合わせて作ってみましょう。
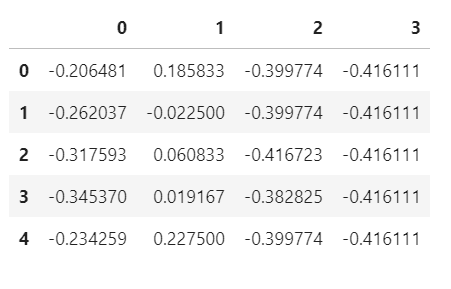
df0 = df.iloc[:,:-1] # 毎回スライスするのはくどいので別の変数に代入しておきます。 df3 = (df0 - df0.mean()) / (df0.max() - df0.min()) df3.head()
[出力結果]
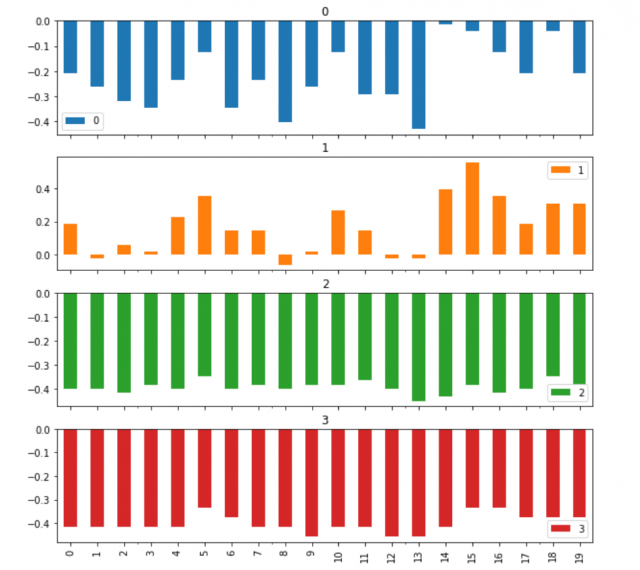
ちなみにこれを可視化すると以下のようになります。
df3[:20].plot(kind="bar", subplots=True, figsize=(10,10))
[出力結果]
まとめ
どうだったでしょうか。pandasのDataFrameにはこの他にも、欠損値を埋める関数や、np.whereのような機能などのたくさんのデータ処理に向いた機能が揃っています。実際のデータ解析に使うデータがirisデータのようにきれいであることは滅多にありません。
そんなときにDataFrameを使えば、比較的簡単にデータを整形することができちゃいます! (このあたりについては侍エンジニアのマンツーマンレッスンでもよく解説する内容です。)
この記事をとっかかりにして、pandasの使い方を勉強してみてください!




