

以前、機械学習を使ったクラス分類について解説しました。

上記の記事では、
- そもそもクラスタリングとはなんなのか
- 代表的なクラスタリング手法であるk-nnの紹介
- scikit-learnを使ってk-nnの実装を試す
という内容で解説しました。
さて、この記事では、実際にPythonとNumpyを使ってk-nn(k近傍法)を実装していきます。
scikit-learnは様々なアルゴリズムが実装されている素晴らしいライブラリですが、勉強のため・拡張のために自分で実装することも大切です。
この記事の解説を読んでk-nnをマスターしましょう!
※ この記事のコードはPython 3.7, NumPy 1.15で動作確認しました。
k-nnをNumpyで実装

k-nnをPythonとNumpyのみを使って実装しながら、このアルゴリズムがどういう仕組みでクラス分類を行っているのかしっかりと理解して行きましょう!
ライブラリのimport
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from collections import Counter
今回使うライブラリをそれぞれ確認していきましょう。
- Numpy
- 計算を行うメインのライブラリ。
- 様々な数式の操作に対応した便利な関数があるため、基本的にどんな機械学習モデルの実装でも使います。
- Pandas
- データの読み込みや前処理などの機能がまとめられたライブラリ。
- この記事ではデータセットの中身を見るためだけに使っているので、なくてもOKです。
- scikit-learn
- 様々な機械学習モデルの実装が収められたライブラリ。
- データセットをダウンロードして読み込むための関数を使うためにimportしています。
- matplotlib
- Pythonの可視化ライブラリ。
- Pandasの.plotメソッドだけでも可視化はできます。
- collections
- 今回k-nnの実装でズルをするために使うライブラリ。
- リストのようなデータ形式の中の要素の数え上げを行う機能が実装されています。
データの読み込み
k-nnでクラス分類を行うデータを読み込みます。
k-nnが正しく動いているかどうかを確認したいので、iris datasetを使います。
iris = datasets.load_iris()
df = pd.DataFrame(
iris.data,
columns = iris.feature_names
)
df["label"] = iris.target
df.head()
このデータは0~2までの三クラスに対して、それぞれ50個のデータが収められていました。
ここで、教師データとテストデータに分けるために、データセットをシャッフルしておきます。
df = df.sample(frac=1).reset_index(drop=True) df.head()
このデータを二つに分割して、片方を教師データ、もう片方をテストデータとして使います。
train_size = 75 train_data = df.iloc[:train_size].values test_data = df.iloc[train_size:].values
k-nnの実装
それではk-nnの実装を見ていきましょう。
sickit-learnでは、knnもクラスとして実装されていました。
ですがここではシンプルに実装するために、ただの関数にしています。
Numpyの機能を使うことで、非常にスッキリとした実装になりました。
コメントで解説をつけたので読んでみてください!
def knn(k, train_data, test_data):
labels = []
for test in test_data:
# 1. すべてのトレインデータとtest(このループステップでラベルを予測したいデータ)との距離を計算したリストを作る
distances = np.sum((train_data[:,:-1]-test[:-1])**2, axis=1)
# 2. 距離リストの値が小さい順に並べた、トレインデータのインデックスを持つリストを作る
sorted_train_indexes = np.argsort(distances)
# 3. インデックスリストを元に、testから近いk個のトレインデータのラベルを取り出す
sorted_k_labels = train_data[sorted_train_indexes, -1][:k]
# 4. sorted_k_labelsの中で最も数の多かったlabelを取り出す
label = Counter(sorted_k_labels).most_common(1)[0][0]
labels.append(label)
return labels
k-nn関数は、この1~4の工程をすべてのテストデータに対して行います。
以下、コメントの補足です。
-
- ここで1の距離の計算は単純にユークリッド距離(一般的に考える距離そのまま)を使っていますが、np.sum関数のaxis引数が何をしているのか考えてみてください。
-
- np.argsortは普通にソートした後、各要素のindexが入った配列を返してくれます。
- np.sortなどのnumpyのsort関数には、pythonのsort, sortedのようなkey引数がないことに注意してください。
-
- インデックスの-1は一番最後の要素を参照しています(ここでは一番最後の要素にクラスラベルが入っています)
-
- 近い順にk個のデータを取り出して、この中で最も数が多いラベルをtestの予測ラベルとします。
- 最も数が多いラベルを探すのに、Counterクラスのmost_commonメソッドを使っています。
Counterクラスについては以下の記事で解説しているので、不安な方は読んでみてください。

結果の確認
結果をチェックしてみましょう。
この関数の実行は以下のように行います。
pred_labels = knn(2, train_data, test_data)
正答率を計算してみます。
np.sum(pred_labels == test_data[:,-1]) / len(test_data) # 出力結果 0.9733333333333334
教師データが全体の半分程度ですが、きれいなデータセットなのもあってかなりいいスコアになっていますね。
可視化もしてみましょう。
まずは正解ラベルで色付けした可視化です。
test_df = df.iloc[train_size:].copy()
test_df["pred_label"] = pred_labels
test_df.plot(kind="scatter", x=0,y=1,c="label", cmap="winter")
plt.title("true label")
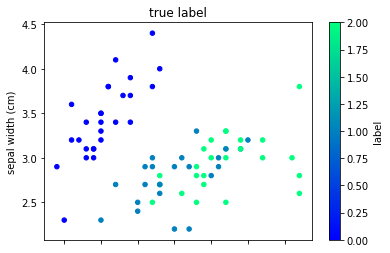
次に予測ラベルで色付けした可視化です。
test_df.plot(kind="scatter", x=0,y=1,c="pred_label", cmap="winter")
plt.title("prediction label")
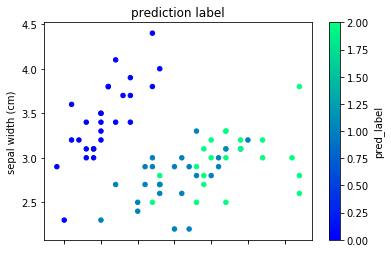
ほとんど同じ結果になっていることがわかりますね。
以上がk-nnのPython実装の紹介でした。
まとめ
この記事ではk-nnをPython・Numpyを使って実装しました。
k-nnはクラス分類の代表的なアルゴリズムです。
簡単ですが意外と奥の深いアルゴリズムです。
普段はscikit-learnを使うとしても、一度自分で実装してみると深い理解ができることでしょう。
是非しっかりと覚えて使いこなしてください!




