

自然言語処理や情報検索の分野に、トピックモデルという手法があります。トピックモデルは文書分類や推薦システムなどに応用できる技術です。詳しくは以下を参考にしてください。

トピックモデルは非常に難しい(と個人的に思う)手法ですが、Pythonではgensimというライブラリを使うことで簡単に使うことができます。この記事ではそんなgensimについて、その基本的な使い方をご紹介します!
gensimとは
gensimは、様々なトピックモデルを実装したPythonライブラリです。「topic modeling for humans」とあるように、実装が大変なトピックモデルを簡単に使うことができます。
- LSI(Latent Semantic Indexing)
- LDA(Latent Dirichlet Allocation)
- DTM(Dynamic Topic Modeling)
などのトピックモデルが実装されています。また、word2vecのようなword embedding手法もgensimから使うことができます。
gensimの基本的な使い方
gensimの基本的な使い方を紹介していきます。
簡単な流れとしては
- 文書データの前処理
- 文書データから辞書(単語とそれに対応したインデックスの辞書)を作る
- カウントベースやTF-IDFなどの方法を使って文書データを変換する
- LDAなどのトピックモデルが実装されたクラスに2で作ったオブジェクトを渡して学習する
の4ステップです。ここではそれに加えて、トピックモデルの結果の可視化まで行ってみる一連の実験を行います。この実験を通してgensimの使い方を確認しましょう。
ステップ1:前処理
ここでは文書データを読み込んで、文書データから辞書を作成します。まずはライブラリをimportしましょう。
import gensim import numpy as np from collections import Counter from sklearn import datasets import matplotlib.pyplot as plt from wordcloud import WordCloud
次に、データセットを読み込みます。
print("Loading dataset...")
twenty_news = datasets.fetch_20newsgroups(shuffle=True, random_state=1,
remove=('headers', 'footers', 'quotes'))
scikit-learnを使ってデータを読み込みます。ここで読み込んだのは20new groupsという、文書データを収めたデータセットです。文書分類に適したデータセットで、20クラスにラベル付けされたテキストが収められています。
読み込んだデータセットはtwenty_news変数に収められているので、printして中身を確認してください。さて、トピックモデルを使うにあたり、文書データを簡単に前処理してきれいにしなければなりません。まずはストップワードの除去です。
ストップワードはI, am, do, haveのような出現頻度は多いがあまり意味の無い単語のことです。これはストップワードリストを使ってフィルタリングを行うのが簡単です。
ここでは、gistで見つけたストップワードリストを保存して使っています。
with open("stopwords.txt") as f:
stopwords = f.read()
stopwords = stopwords.split()
これでストップワードのリストができたので、これを使ってフィルタリングを行います。つまり、ストップワードリストに入っている単語を消しながら、gensimの入力データの形にデータを整形します。
ちなみにこの時点で、docsの中身はリストの中にstr型が入っている形です。
(※つまり [“文章1”, “文章2”, …] の形)
docs = data.data
texts = [
[w for w in doc.lower().split() if w not in stopwords]
for doc in docs
]
英語には大文字と小文字があります。
これらを全て小文字に直してから、ストップワードリストの中にある単語ならば削除しています。※ここまでで、texts変数は[[“単語”, “単語”, …], [“単語”, “単語”, …], …]の形になっています。
さて、実は文書データの中で使われている単語の出現頻度には偏りが非常に大きいということが知られています。これをグラフを使って確認してみましょう。
count = Counter(w for doc in texts for w in doc) count.most_common()[:10]
[出力結果]
[('-', 6200),
('would', 6074),
('one', 5420),
('x', 4688),
("don't", 3652),
(':', 3649),
('like', 3624),
('get', 3447),
('people', 3387),
("max>'ax>'ax>'ax>'ax>'ax>'ax>'ax>'ax>'ax>'ax>'ax>'ax>'ax>'ax>'", 3289)]
Counterクラスのmost_commonを使うとリストの中の要素が何回出現しているのかを、上のように数え上げてくれます。これを使ってグラフを作ってみました。
y = [i[1] for i in count.most_common()] plt.plot(y)

x軸は単語です(約200000個くらいの単語があります。)yはそれぞれの単語の出現回数です。
本当に一握りの高頻出の単語と、それ以外のほとんど出現しない単語に分かれていますね。また、対数グラフにすると以下のようになります。
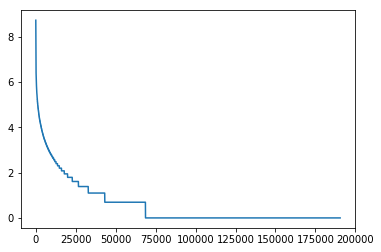
ほとんどの単語が1回しか出ていないようです。トピックモデルを使うとき、一回しか出ていないような本当に低い出現頻度の単語や、めちゃくちゃ出現頻度の高い単語をフィルタリングしてしまうという前処理があります。
ここではそれを採用します。※このコードは簡単にするために、ステップ2, ステップ3を行ってから使いましょう。
num_tokens = len(count.most_common()) N = int(num_tokens*0.05) max_frequency = count.most_common()[N][1] corpus = [[w for w in doc if max_frequency > w[1] >= 3] for doc in corpus]
3回以上出現している or 出現頻度上位5%の単語をフィルタリングしました。
ステップ2:辞書の作成, ステップ3:Corpusの作成
前処理が終わったら、辞書を作成します。gensimで使う辞書の作成には、gensim.corpora.Dictionary関数を使います。この辞書は前述したとおり、単語とindexの組み合わせを持っています。
これを使って、そのまま文書データをgensimで使える形に変換します。この変換にはdoc2vecメソッドを使います。
dictionary = gensim.corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts] corpus[0]
[出力結果]
[(18, 3), (32, 3), (38, 4), (78, 3), (81, 3), (83, 15), (105, 4), (109, 4), (113, 8), (148, 10), ...中略... ]
変換したデータは、indexと出現回数のタプルのリストが文書の分だけ入ったリストになっています。
出力結果をみてください。これは [(単語のindex, 出現回数), …]になっています。このリストで一つの文書に相当するので、corpus変数には、このリストを文書数分だけ内包したリストを持っています。
トピックモデルの学習
ここまででgensimで入力データとして使えるオブジェクト(corpus)ができました。これと辞書オブジェクト(dictionary)を使って、LDAモデルの学習を試してみましょう。
LdaModelクラスを使うには、最低3つのパラメータを設定します。corpus、num_topics, id2wordの3つです。LDAはtopic数を利用者が決める必要があるので、ここはint型で指定してください。
id2wordは辞書オブジェクトを渡せばOKです。
num_topics = 20
lda = gensim.models.ldamodel.LdaModel(
corpus=corpus,
num_topics=num_topics,
id2word=dictionary
)
これで学習ができました。データの大きさによっては時間がかかるので気をつけてください。
結果の確認
トピックを可視化してみましょう。今回はワードクラウドを使って可視化します。単語の大きさがその単語のそのトピックにおける所属確率の高さになります。
plt.figure(figsize=(30,30))
for t in range(lda.num_topics):
plt.subplot(5,4,t+1)
x = dict(lda.show_topic(t,200))
im = WordCloud().generate_from_frequencies(x)
plt.imshow(im)
plt.axis("off")
plt.title("Topic #" + str(t))

左上がtopic0、右下がtopic19になっています。今回はチューニングを適当にしていますし、前処理も最低限ですのであまりきれいにはトピックができていませんね。
しかしtopic14やtopic17のような、なんとなく意味的なまとまりがありそうなトピックもできているようです。これを更にきれいなトピックが作れるようにチューニングしたり、可視化の方法を変えたりといった方法について勉強すると面白いですよ。
まとめ
この記事ではgensimの使い方について、実際に簡単に実験を一通り行うことで紹介しました。gensimにはここで紹介したLDA以外にもたくさんのモデルが実装されています。
Deep Learning以外にも面白い機械学習手法があること、それがgensimなどのライブラリによって手軽に試せることを実感していただけたら嬉しいです。




