

こんにちは、インストラクターのフクロウです。データ解析を行う際に、データ形式がCSVファイルで公開されているとプログラムに読み込みやすくて嬉しいですね。
さて、この記事ではCSVファイルをデータフレームに読み込む方法を紹介します。CSVファイルの読み込みにはpd.read_csv関数を使うことで簡単に試せますよ!
記事で是非使い方を覚えてみませんか?
ヘッダー情報のないcsvファイルの読み取り方
まずはヘッダー情報のないcsvファイルを読み込みましょう。この関数はNumPyのnp.loadtxtとは違い、文字列のカラムと数字のカラムが混じったようなファイルでも読み込みが可能です。
重要なのはheaderプロパティですね。データの解説がファイルの先頭に書かれてないきれいなcsvファイルの場合、header=Noneと指定してあげればOKです。
iris dataset csvファイルの読み込み
まずはCSVファイルを用意します。以下のリンクはUCI Machine Learning Repositoryというサイトへのものです。
このページからデータをcsvファイルをダウンロードして、”iris.csv”という名前で保存しましょう。PythonスクリプトやJupyter NotebookのipynbファイルがあるディレクトリにCSVファイルをおいておくと、読み込みの際に楽です。
ファイルの読み込みはpd.read_csv関数で行います。最初に書いたとおり、headerパラメータをNoneにして実行しましょう。
import pandas as pd
iris = pd.read_csv("iris.csv", header=None)
iris.head()
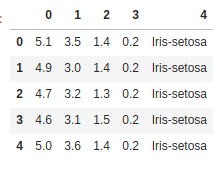
ちゃんと読み込めましたね。このようにheader=Noneとしてやると、CSVから作られたDataFrameのカラム名は自動的にIndexが割り振られます。注意点としては、headerを指定しないと、CSVデータの一行目がカラムの名前に割り当てられることがある点です。
zoo dataset csvファイルの読み込み
同じ要領で、別のデータセットも読み込んでみましょう。zooデータを以下からダウンロードして、”zoo.csv”として保存します。
これを読み込むには以下のコードを使いましょう。
zoo = pd.read_csv("zoo.csv",header=None)
zoo.head()
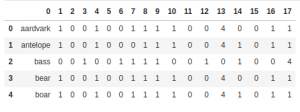
うまく行っていますね。DataFrameとして読み込むと、NumPyよりも柔軟にデータの前処理ができます。データ解析では欠損値への対処や文字列型への操作など、前処理の段階でやっておきたい重要な作業が山積みです。解析の最初の一歩として、DataFrameへのデータセット読み込みはおすすめですよ!
ヘッダー情報のあるcsvファイルの読み取り方
parkinsons dataset csvファイルの読み込み
CSVファイルにヘッダー情報がある場合、headerパラメータにヘッダーの終わりの行を指定します。
例題として、パーキンソン病のデータセットを使います。
これを”parkinsons.csv”として保存します。このデータは以下のような形になっています。
name,MDVP:Fo(Hz),MDVP:Fhi(Hz),MDVP:Flo(Hz),MDVP:Jitter(%),MDVP:Jitter(Abs),MDVP:RAP,MDVP:PPQ,Jitter:DDP,MDVP:Shimmer,MDVP:Shimmer(dB),Shimmer:APQ3,Shimmer:APQ5,MDVP:APQ,Shimmer:DDA,NHR,HNR,status,RPDE,DFA,spread1,spread2,D2,PPE phon_R01_S01_1,119.99200,157.30200,74.99700,0.00784,0.00007,0.00370,0.00554,0.01109,0.04374,0.42600,0.02182,0.03130,0.02971,0.06545,0.02211,21.03300,1,0.414783,0.815285,-4.813031,0.266482,2.301442,0.284654 phon_R01_S01_2,122.40000,148.65000,113.81900,0.00968,0.00008,0.00465,0.00696,0.01394,0.06134,0.62600,0.03134,0.04518,0.04368,0.09403,0.01929,19.08500,1,0.458359,0.819521,-4.075192,0.335590,2.486855,0.368674 phon_R01_S01_3,116.68200,131.11100,111.55500,0.01050,0.00009,0.00544,0.00781,0.01633,0.05233,0.48200,0.02757,0.03858,0.03590,0.08270,0.01309,20.65100,1,0.429895,0.825288,-4.443179,0.311173,2.342259,0.332634 ...こういう行がこの下にずらっと続く
headerとしてCSVの各列の名前が書かれていますね。こんなときはheader=0としてあげればOKです。
parkinsons = pd.read_csv("parkinsons.csv", header=0)
parkinsons.head()
![]()
ヘッダー情報があるならば、カラムの名前もCSVファイルを読み込むだけで設定できます。
まとめ
この記事では、PandasでCSVファイルを読み込む方法を解説しました。Pandasはデータ解析において広く使われているツールです。これを使うことで前処理の手間が効率化できるのが嬉しいですね。
是非使ってみてくださいね!




