

こんにちは!インストラクターのフクロウです!Pandasでデータをエイヤッといろいろ操作した後に、データを保存しておきたい時があります。
そんなときには、データフレームをCSVファイルに保存できるto_csvメソッドがおすすめです!データ解析・機械学習、やって終わりじゃもったいない!
この記事でto_csvをマスターして、Pythonプログラムで作ったデータをファイルとして保存するという作業をあなたの機械学習ライフに追加してみましょう!
データ解析や機械学習を楽しむ中で、成果をしっかりと形に残すことはとても重要です。しかし、技術の進化は止まらず、AIがもたらす未来に備えることもまた必要です。もし、「自分一人では難しいかも…」と感じたなら、より広い視野でスキルを活かせる環境を考えてみるのも良いでしょう。
AIとWeb制作のスキルを組み合わせることで、あなたのキャリアや収入に新たな可能性が広がります。実践的なノウハウを学べる機会を活用すれば、机上の空論ではない、すぐに役立つスキルを身につけることができます。
少しでも興味を持たれた方は、詳細なセミナー情報を確認して、自分に合った方法を探してみませんか?
開発環境
この記事を書くために使った開発環境は以下のとおりです。
- OS=”Ubuntu 18.04.1 LTS”
- Python 3.7.0
- Pandas 0.23.4
OSが異なっても基本的には同じ操作で記事中のプログラムは再現できるので、試してみてください!
to_csvのAPI
to_csvはDataFrameのメソッドです。引数や返り値の詳しい解説は以下のページを参照してください。
上のページは公式ドキュメントですが、引数がたくさんあって混乱しちゃうかもしれません。次の章で特に大切な部分の使い方を紹介していきます!
また、この関数はCSVに書き出す機能ですが、逆にCSVから読み込む関数もあります。これについては以下の記事解説していますよ!

to_csvの使い方
[前準備]DataFrameの作成
まずライブラリをimportします。
In [1]:
import pandas as pd
import numpy as np
from sklearn import datasets
機械学習ライブラリsklearnから、iris datasetsを読み込んでDataFrameを作ります。
# sklearnからデータセットを読み込みます
iris = datasets.load_iris()
# データセットからDataFrameを作成します。ここでは列が特徴になっていて、クラスをlabel列として追加しておきます。
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["lable"] = [iris.target_names[i] for i in iris.target]
df.head()
CSVファイルにDataFrameを書き出す
まずは最低限の使い方。to_csvメソッドに作りたいCSVファイルの名前を渡すだけで、CSVファイルが作れます。ちなみに、区切り文字がカンマ「,」になっているのがCSVファイルです。
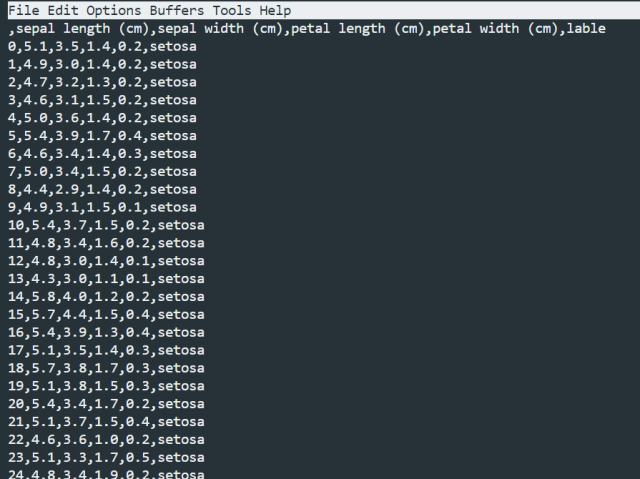
df.to_csv("./iris1.csv")
保存したファイルは以下のような形になっています。
区切り文字を変える
カンマ以外の区切り文字が使いたい場合を考えてみましょう。例えばTABを使いたい場合(TSVファイルと呼びます)などは、to_csvのsep引数を使います。
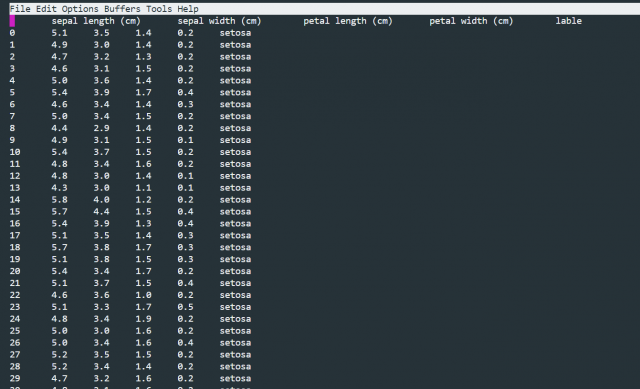
df.to_csv("./iris2.tsv", sep="t") # tはTABを表す特殊な記号です。
保存したファイルを見てみましょう。
ヘッダーやインデックスの扱い
DataFrameには行のインデックスや、列の名前などを扱えます。これらをCSVファイルに保存するときにどう扱うかはheader引数やindex引数で決められます。
デフォルトではどちらもCSVファイルに書き込むことになっていますが、これらの情報を削除する方法を見てみましょう。
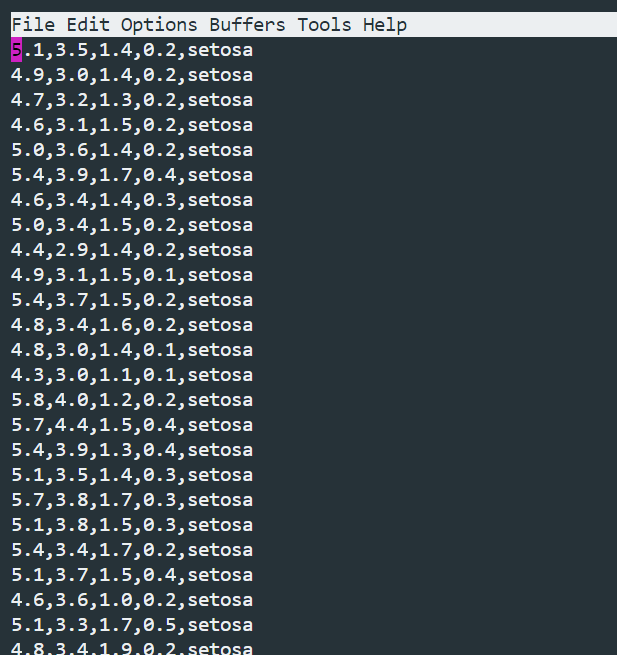
df.to_csv("./iris3.csv",
header=False, # ヘッダー情報を削除
index=False # 行インデックスを削除
)
まとめ
この記事ではPandasのDataFrameをCSVファイルに保存する方法を解説しました。CSVファイルへの保存の要点は、
- df.to_csvメソッドを使う
- sep引数で区切り文字を変えられる
- header/index引数のTrue/Falseで行や列の名前を保存するかどうか操作できる
です。簡単なのでどんどん使ってみてくださいね!




