

こんにちは!システムエンジニアのオオイシです。
SQLのDISTINCT(ディスティンクト)をご存知ですか?DISTINCTの使い方を覚えると、SELECT文の実行結果の重複レコード(データ行)を1つにまとめることができます。
この記事では、
- DISTINCTとは
- DISTINCTの使い方
- 複数列でDISTINCTを使ってみる
- DISTINCTする列が1つの場合のレコード件数取得方法
- DISTINCTする列が複数の場合のレコード件数取得方法
などの基本的な解説から応用的な使い方関しても解説していきます。
今回はそんなDISTINCTの使い方をわかりやすく解説します!
DISTINCTとは
DISTINCTとは、SELECT文の実行結果の重複レコード(データ行)を1つにまとめるための便利な構文です。
例えば、従業員テーブルに「姓、名」の項目があるとして、同姓同名が複数行ある場合にDISTINCTを使うと次のように1レコードになります。
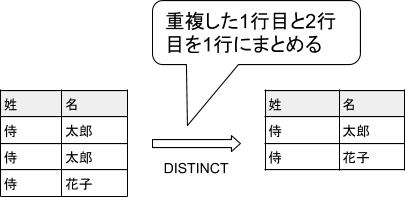
そんなDISTINCTの使い方を次項で解説していきます!
DISTINCTの使い方
DISTINCTの構文はSELECT文の後に追加して、次のように記述します。
- SELECT DISTINCT 列名,列名… FROM テーブル名
従業員テーブルの「姓(last_name)」を検索する例について、DISTINCTを使わない場合と使う場合の2つを比較したサンプルコードを確認してみましょう。
サンプルデータの作成:
CREATE TABLE sample1_employees (
no int NOT NULL, -- 従業員番号
last_name varchar(255), -- 名
first_name varchar(255), -- 姓
PRIMARY KEY (no) -- 主キー
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- テストデータ
INSERT INTO sample1_employees VALUES('10001', '侍','太郎');
INSERT INTO sample1_employees VALUES('10002', '侍','太郎');
INSERT INTO sample1_employees VALUES('10003', '侍','次郎');
DISTINCTを使わない場合:
mysql> SELECT last_name from sample1_employees; +-----------+ | last_name | +-----------+ | 侍 | | 侍 | | 侍 | +-----------+ 3 rows in set (0.00 sec)
DISTINCTを使う場合:
mysql> SELECT DISTINCT last_name from sample1_employees; +-----------+ | last_name | +-----------+ | 侍 | +-----------+ 1 row in set (0.00 sec)
このように、DISTINCT を使うと重複レコードを1つにまとめることができました。
次に、SELECTが複数の列のときにDISTINCTを使うとどのようになるか解説していきます。
複数列でDISTINCTを使ってみる
SELECT文で複数列の検索結果が得る場合にDISTINCTを使うと、レコード(データ行)単位に重複行がまとめられます。
従業員テーブルの「姓(last_name)と名(first_name)」を検索する例について、DISTINCTを使わない場合と使う場合の2つを比較したサンプルコードを確認してみましょう。
DISTINCTを使わない場合:
mysql> SELECT last_name, first_name from sample1_employees; +-----------+------------+ | last_name | first_name | +-----------+------------+ | 侍 | 太郎 | | 侍 | 太郎 | | 侍 | 次郎 | +-----------+------------+ 3 rows in set (0.00 sec)
DISTINCTを使う場合:
mysql> SELECT DISTINCT last_name, first_name from sample1_employees; +-----------+------------+ | last_name | first_name | +-----------+------------+ | 侍 | 太郎 | | 侍 | 次郎 | +-----------+------------+ 2 rows in set (0.00 sec)
このように、「姓(last_name)と名(first_name)」の2列で同じレコードは1レコードにまとめて表示できることが確認できました。
次に、DISTINCTした結果のレコード件数を調べる方法について解説していきます。
DISTINCTとCOUNTを併用して使ってみる
DISTINCTして検索したレコード件数を数えるためには、件数を数えるCOUNT関数を併用します。
COUNT関数の構文は、次のように、
- SELECT COUNT(列名) FROM テーブル名
と書きますが、引数が1つだけなので、列名が複数の場合は工夫が必要です。
今回は、DISTINCTを使ったCOUNT文を使う方法を2つ紹介していきます。
DISTINCTする列が1つの場合のレコード件数取得方法
SELECTする列が1つの場合は、次のようにシンプルに記述できます。
- SELECT COUNT(DISTINCT 列名) from テーブル名
従業員テーブルの「姓(last_name)」をDISTINCTで重複を1つにまとめた上で、レコード件数を数えるサンプルコードを確認してみましょう。
COUNTを使う前:
mysql> SELECT DISTINCT last_name from sample1_employees; +-----------+ | last_name | +-----------+ | 侍 | +-----------+ 1 row in set (0.00 sec)
COUNTを使った結果:
mysql> SELECT COUNT(DISTINCT last_name) from sample1_employees; +---------------------------+ | COUNT(DISTINCT last_name) | +---------------------------+ | 1 | +---------------------------+ 1 row in set (0.00 sec)
このように、DISTINCTした結果の件数を数えることができました。
つづいて、SELECTする列が複数の場合について解説していきます。
DISTINCTする列が複数の場合のレコード件数取得方法
SELECTする列が複数の場合は、列と列が1つになるように繋いだ上で、DISTINCTで重複を除きます。
列と列を繋げるためにはCONCAT関数を併用して、
- SELECT COUNT( DISTINCT CONCAT(列名,列名…) FROM テーブル名
のように記述します。
従業員テーブルの「姓(last_name)と名(first_name)」をSELECT文で検索し、DISTINCTしたデータ件数を数えるサンプルコードを確認してみましょう。
はじめに、COUNTを使わずにCONCATして列をつなぎ合わせた結果を見てみます。
SELECT
DISTINCT CONCAT(last_name, first_name) result
FROM
sample1_employees
実行結果:
+-----------+ | result | +-----------+ | 侍太郎 | | 侍次郎 | +-----------+ 2 rows in set (0.00 sec)
同姓同名の2件のレコードがCONCATで姓名が連結されて検索できました。
これをCOUNTを追加して件数を数えてみます。
SELECT COUNT(
DISTINCT CONCAT(last_name, first_name)
) result
FROM
sample1_employees
実行結果:
+--------+ | result | +--------+ | 2 | +--------+ 1 row in set (0.00 sec)
このように、複数列の場合でもDISTINCTで重複を削除して件数を数えることができました。
まとめ
いかかでしたか?
今回はSQLのDISTINCTについて解説しました。DISTINCTは、SELECT文の重複レコード(データ行)を1つにまとめる便利な構文です。
DISTINCTはSQLを利用する上でよく使う構文なので、ぜひ習得してみてはいかがでしょうか。そして、DISTINCTの使い方を忘れてしまったらこの記事を確認してくださいね!




