

今回は、2017年6月にGoogleが公開したTensorFlow Object Detection APIを試してみます。
TensorFlow Object Detection APIは、TensorFlowで手書き数字(MNIST)は認識できたけど、あまり面白くない!と感じたあなたにピッタリのAPIです。
百聞は一見にしかず、こんな画像を渡すと…

South Haven, Day 3
引用:Michael Miley, https://www.flickr.com/photos/mike_miley/4678754542/in/photolist-88rQHL-88oBVp-88oC2B-88rS6J-88rSqm-88oBLv-88oBC4
こんな風に何が写っているか教えてくれるという優れものです!

自分が持っている写真で試してみたくなりましたね?
この記事の最後では、自分が持っている写真を試す方法も紹介していますので、1つずつ辛抱強く作業を進めてください。
では、始めましょう。
TensorFlow Object Detection APIを試してみて、その便利さに驚かれた方も多いでしょう。しかし、「これをどう収入に繋げるか?」と疑問に思う方もいるのではないでしょうか。そんな方には、新しいスキルを学ぶ絶好の機会を活用することをおすすめします。生成AIとWeb制作を組み合わせたスキルは、今後のキャリアに大きなプラスをもたらします。
この分野で得られる実践的なスキルは、すぐに仕事に活かせる具体的なノウハウが満載です。AIがもたらす未来を見据え、今から始めることが重要です。興味がある方は、まずはセミナーの詳細を確認してみませんか?
TensorFlow Object Detection APIとは
TensorFlow Object Detection APIは、TensorFlowを利用して、画像に写っている物体を検出するためのフレームワークです。
以下の記事で取り扱っていた、MNISTやCIFAR-10では、1枚の写真に1つの何かが写っているという前提で、何が写っているかを答えさせていました。


今回紹介するTensorFlow Object Detection APIでは、1枚の写真に複数の何かが写っているという前提で、どこに何が写っているかを答えさせます。
Windowsにインストールする
Windows 10にTensorFlow Object Detection APIを使用するために必要な環境を整えていきましょう。
公式の情報は、Linux向けに書かれているため、そのままの手順ではWindowsにはインストールできません。
そこで、私が実際にWindows 10にインストールした方法を説明します。
TensorFlow Modelsをダウンロードする
GitHubのTensorFlow Modelsリポジトリをダウンロードします。
(1)https://github.com/tensorflow/modelsにアクセスし、「Clone or download」→「Download ZIP」の順にクリックします。
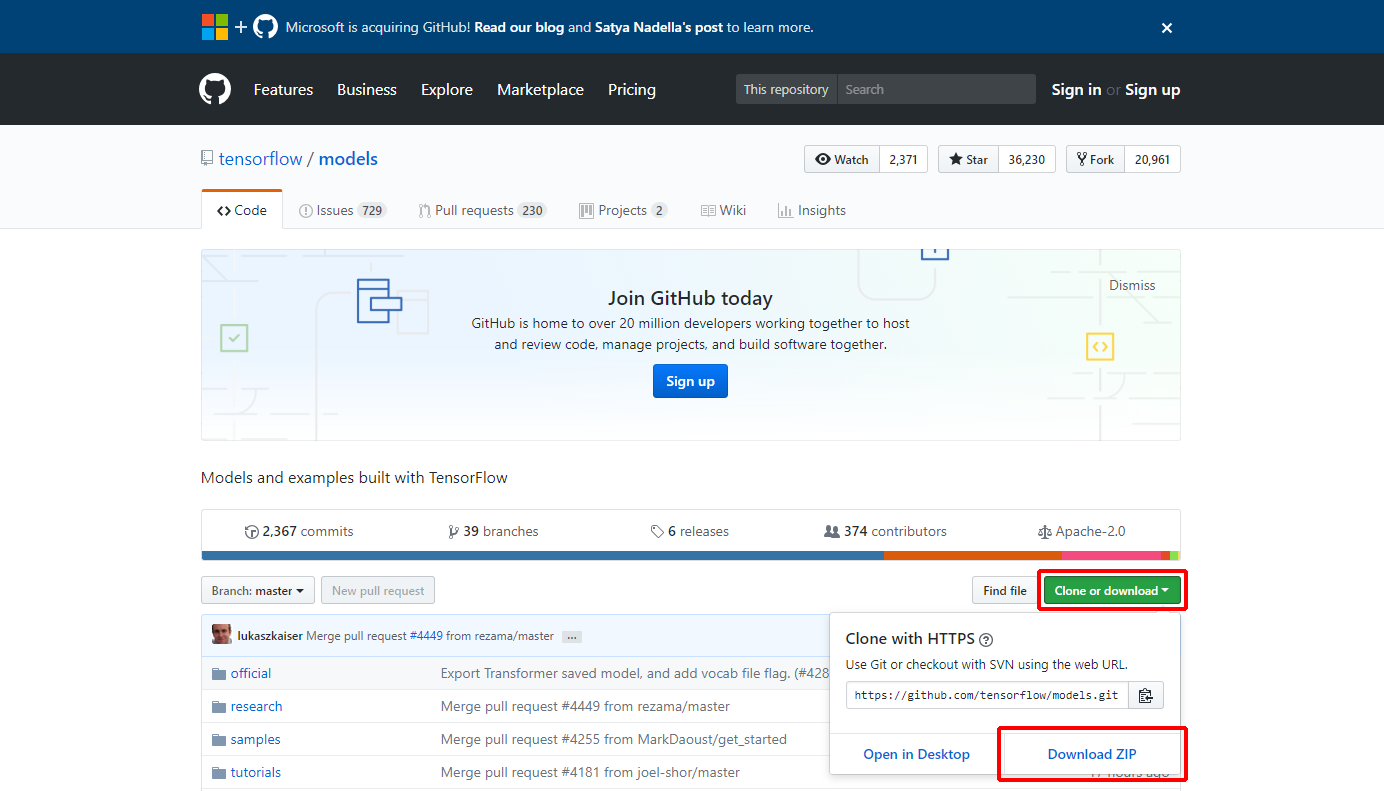
models-master.zipがダウンロードされます。
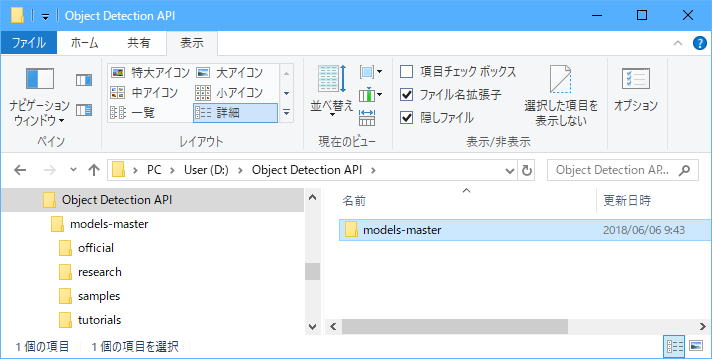
(2)models-master.zipを「D:\Object Detection API」フォルダに展開します。
展開した結果は以下のとおりです。
Protocol Buffersのコンパイラ(protoc.exe)をインストールする
Protocol Buffersのコンパイラ(protoc.exe)を、GitHubのProtobufリポジトリからダウンロードし、指定したフォルダにコピーします。
(1)https://github.com/google/protobuf/releasesにアクセスして、「protoc-3.5.1-win32.zip」をクリックします。
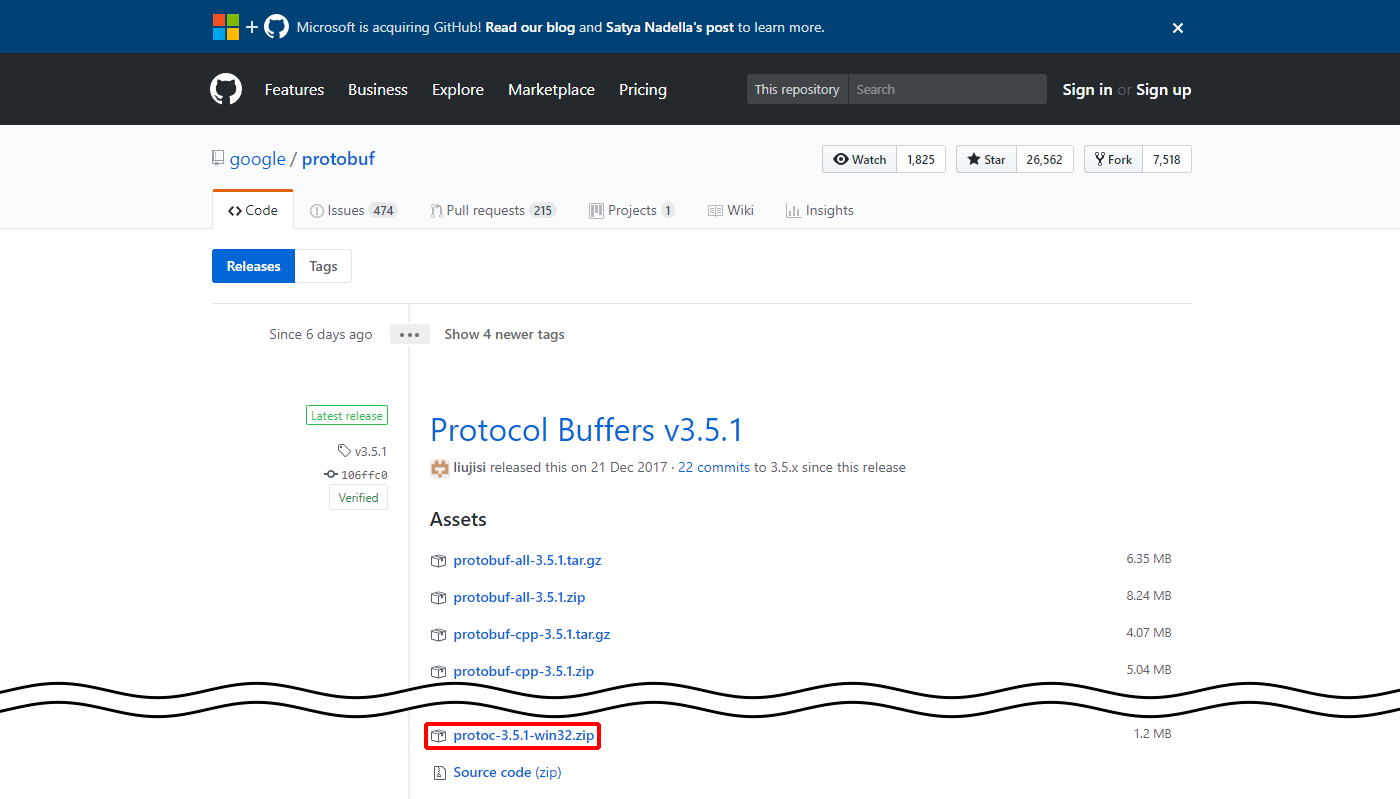
protoc-3.5.1-win32.zipがダウンロードされます。
(2)protoc-3.5.1-win32.zipを展開し、「bin」フォルダの「protoc.exe」を、「D:\Object Detection API\models-master\research」フォルダにコピーします。
GPU版TensorFlowをインストールする
やはり速さが大事でしょう、ということで、Windows 10にAnacondaをインストールし、tensorflow-gpu環境を作成して、GPU版TensorFlowをインストールします。
インストール方法は、以下の記事で詳しく説明されていますので、ぜひ参考にしてください。

必要なライブラリをインストールする
続けて、TensorFlow Object Detection APIの実行に必要なライブラリをインストールしましょう。
Anaconda Navigatorを起動し、GPU版TensorFlowをインストールしたPython環境を起動して、ライブラリをインストールする操作を説明します。
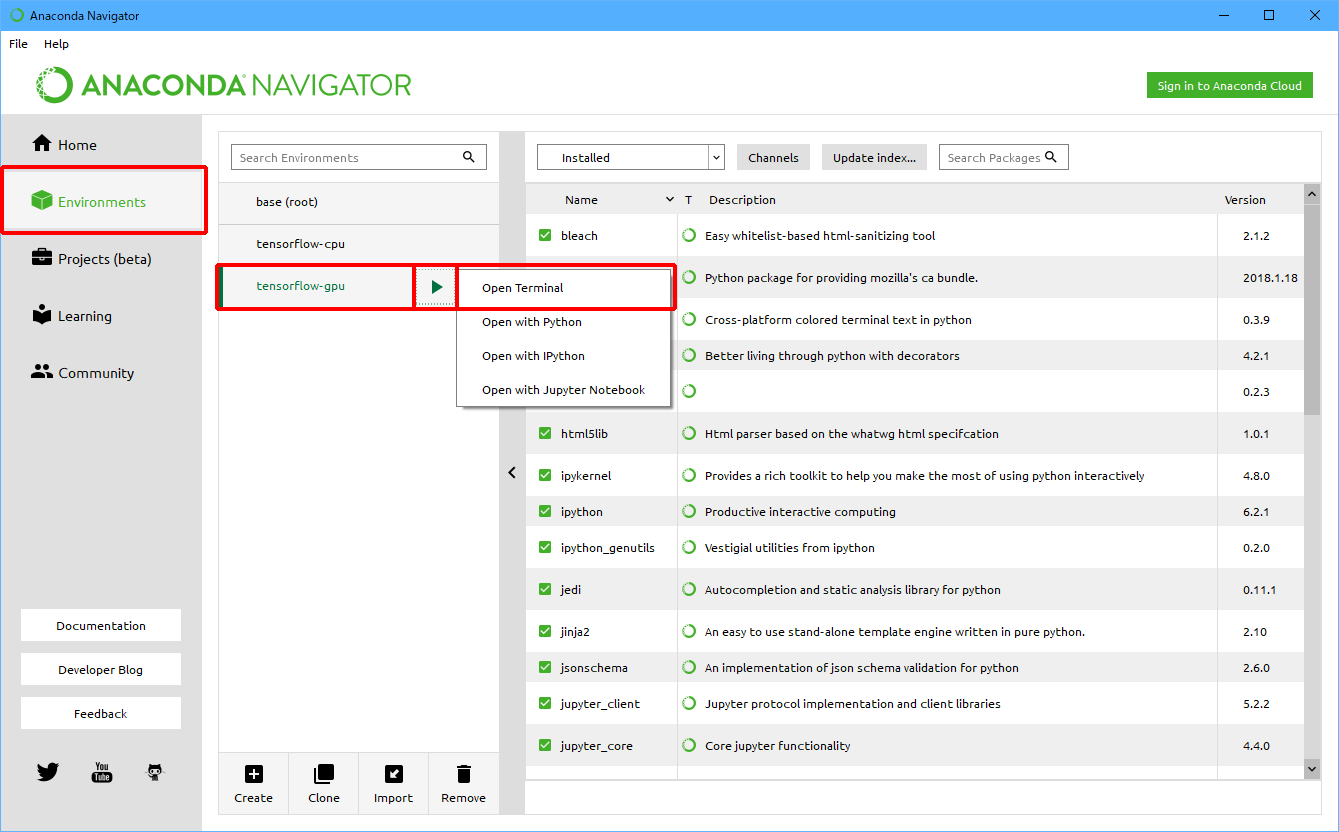
(1)Anaconda Navigatorを起動します。
(2)「Environment」をクリック後、「tensorflow-gpu」をクリックし、「![]() 」をクリックして、「Open Terminal」をクリックします。
」をクリックして、「Open Terminal」をクリックします。
(3)コマンドプロンプトが起動したら、以下のコマンドを1行ずつ入力します。
pip install Cython pip install pillow pip install lxml pip install jupyter pip install matplotlib
Anacondaのtensorflow-gpu環境にmodels-masterを登録する
Anacondaで作成したtensorflow-gpu環境に、以下の2つのフォルダを登録します。
- D:\Object Detection API\models-master\research
- D:\Object Detection API\models-master\research\Slim
(1)「C:\Users\(ユーザー名)\Anaconda3\envs\tensorflow-gpu\Lib\site-packages」フォルダに、models-master.pthファイルを作成します。
models-master.pthファイルの内容は以下のとおりです。
D:\Object Detection API\models-master\research D:\Object Detection API\models-master\research\Slim
Anacondaを使用しているとsite-packagesフォルダはたくさんありますが、今回はtensorflow-gpu環境にインストールしていますので、「tensorflow-gpu」フォルダの中の「site-packages」フォルダにpthファイルを作成します。
(2)設定を反映するために、Anacondaのtensorflow-gpu環境をいったん終了します。
Protobufをコンパイルする
Protocol Bufferでは、protoファイルを作成して構造を定義し、protoc.exeを使ってprotoファイルをコンパイルします。
以下の手順で、初めにダウンロードしたTensorFlow Modelsに用意されているprotoファイルをコンパイルしましょう。
(1)Anaconda Navigatorを起動します。
(2)「Environment」をクリック後、「tensorflow-gpu」をクリックし、「![]() 」をクリックして、「Open Terminal」をクリックします。
」をクリックして、「Open Terminal」をクリックします。
(3)「D:」と入力し、Enterキーを押します。
(4)「cd D:\Object Detection API\models-master\research」と入力し、Enterキーを押します。
(5)「for /r %v in (object_detection/protos/*.proto) do protoc "object_detection/protos/%~nxv" –python_out=.」と入力し、Enterキーを押します。
※protoc 3.4を使用している場合は「protoc object_detection/protos/*.proto –python_out=.」と入力して、Enterキーを押してもコンパイルできます。
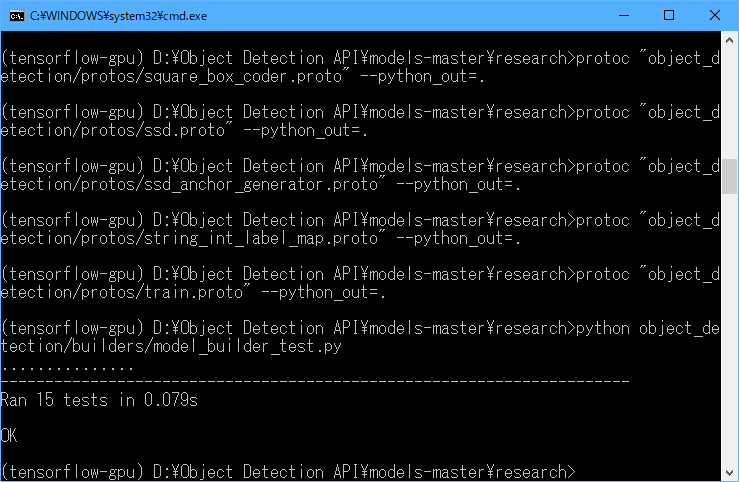
(6)「python object_detection/builders/model_builder_test.py」と入力し、Enterキーを押します。
以下のように「OK」と表示されればインストール完了です。
TensorFlow Object Detection APIを実行する
さて、いよいよですよ。
チュートリアルプログラム(object_detection_tutorial.ipynb)を実行して、写真に写っている複数の何かを検出してみましょう!
(1)先ほどの手順に続けて、「jupyter notebook」と入力し、Enterキーを押します。
(2)「object_detection」をクリックします。
(3)「object_detection_tutorial.ipynb」をクリックします。
(4)「Cell」→「Run All」の順にクリックします。
少し時間がかかりますが、最後のセルに結果が表示されます。
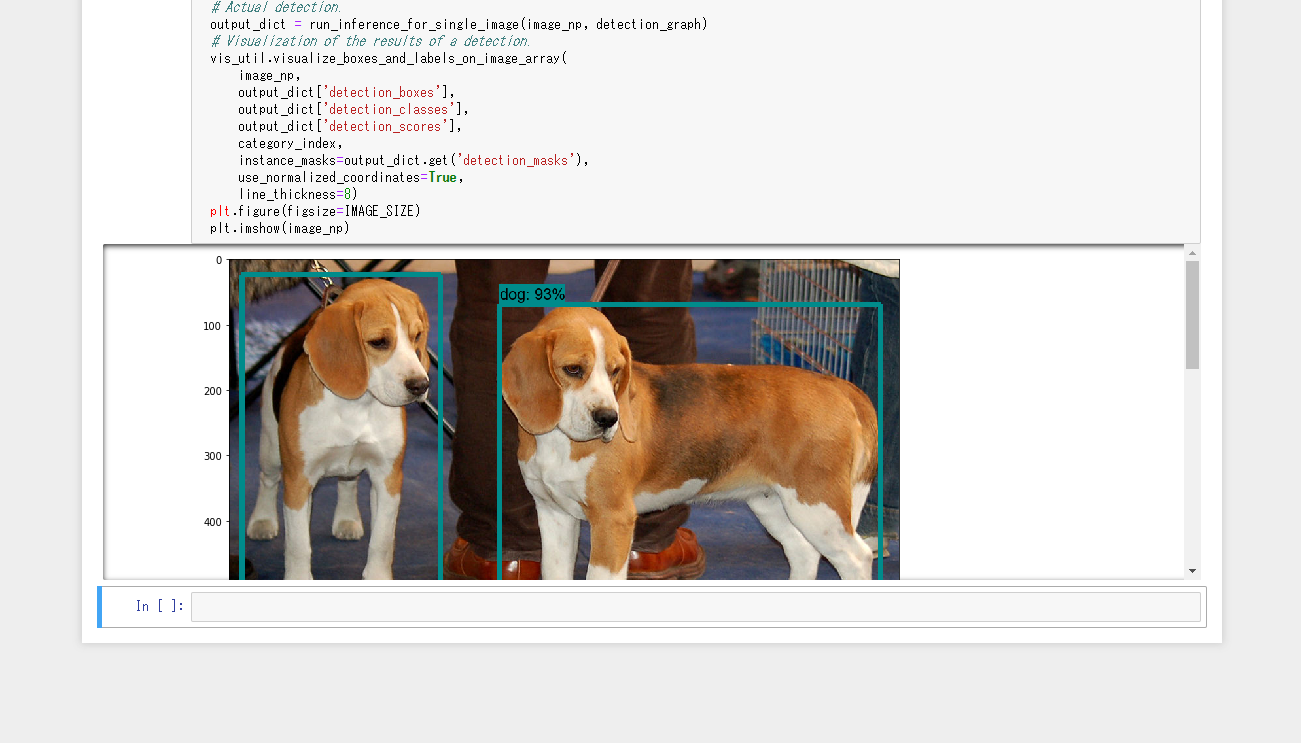
犬の部分が囲まれてdogと表示されていますね!
任意の画像で試す
最後に、チュートリアルプログラムを変更して、任意の画像で写っているモノを検出する方法を説明しましょう。
(1)上で説明した手順に従い、Jupyter Notebookでobject_detection_tutorial.ipynbを開き、以下のセルの内容を変更します。
変更前:
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
変更後:
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ]
from pathlib import Path
PATH_TO_MY_TEST_IMAGES_DIR = "D:\Object Detection API\Test Images"
p = Path(PATH_TO_MY_TEST_IMAGES_DIR)
TEST_IMAGE_PATHS.extend(p.glob("*.jpg"))
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
(2)「D:\Object Detection API\Test Images」フォルダを作成し、任意のJPEG形式の画像ファイル(拡張子:.jpg)を保存します。
(3)Jupyter Notebookで「Cell」→「Run All」の順にクリックします。
以下の写真で試したところ…

以下のように表示されました。

ちょっと分かりにくいですが、person以外に、bedも検出できていて、驚きました。
まとめ
今回は、TensorFlow Object Detection APIをインストールして、チュートリアルプログラム(object_detection_tutorial.ipynb)を動かす操作を説明しました。
さらに、任意のJPEGファイルに何が写っているか検出できるようにチュートリアルプログラムを変更し、実際に検出してみました。
この記事の内容を理解できたら、次はTensorFlow Object Detection APIを応用して、動画に何が写っているかを(概ね)リアルタイムに検出することに挑戦してみてはいかがでしょうか。
それでは、今回はこの辺りで終わりにしましょう。




