

こんにちはフクロウです。Pythonのインストラクターをやっています。
今回の記事では、実際にPythonとNumpyを使ってk-means(k平均法)を実装していきます。scikit-learnは様々なアルゴリズムが実装されている素晴らしいライブラリですが、勉強のため・拡張のために自分で実装することも大切です。
さて、以前、機械学習を使ったクラスタリングについて解説しました。

上記の記事では、
- そもそもクラスタリングとはなんなのか
- 代表的なクラスタリング手法であるk-meansの紹介
- scikit-learnを使ってk-meansの実装を試す
という内容で解説しました。
この記事ではscikit-learnを使わずに、自力での実装を目指します。この記事を読んでk-meansをマスターしましょう!
※ この記事のコードはPython 3.7, NumPy 1.15で動作確認しました。
PythonとNumpyを使ってk-meansを実装することに興味を持たれた方も多いかもしれませんね。しかし、プログラミングスキルをさらに活かして収入を得るためには、生成AIやWeb制作のスキルも重要です。これらを組み合わせることで、独立や副業の道が開けることをご存知でしょうか。
このセミナーでは、生成AIとWeb制作を駆使して稼ぐための具体的なノウハウをお伝えします。机上の空論ではなく、実践的なスキルを身につけることで、AIが変える未来に乗り遅れない準備を整えましょう。
少しでも興味を持たれた方は、セミナーの詳細を確認して、自分に合った方法を探してみませんか?
k-meansとは
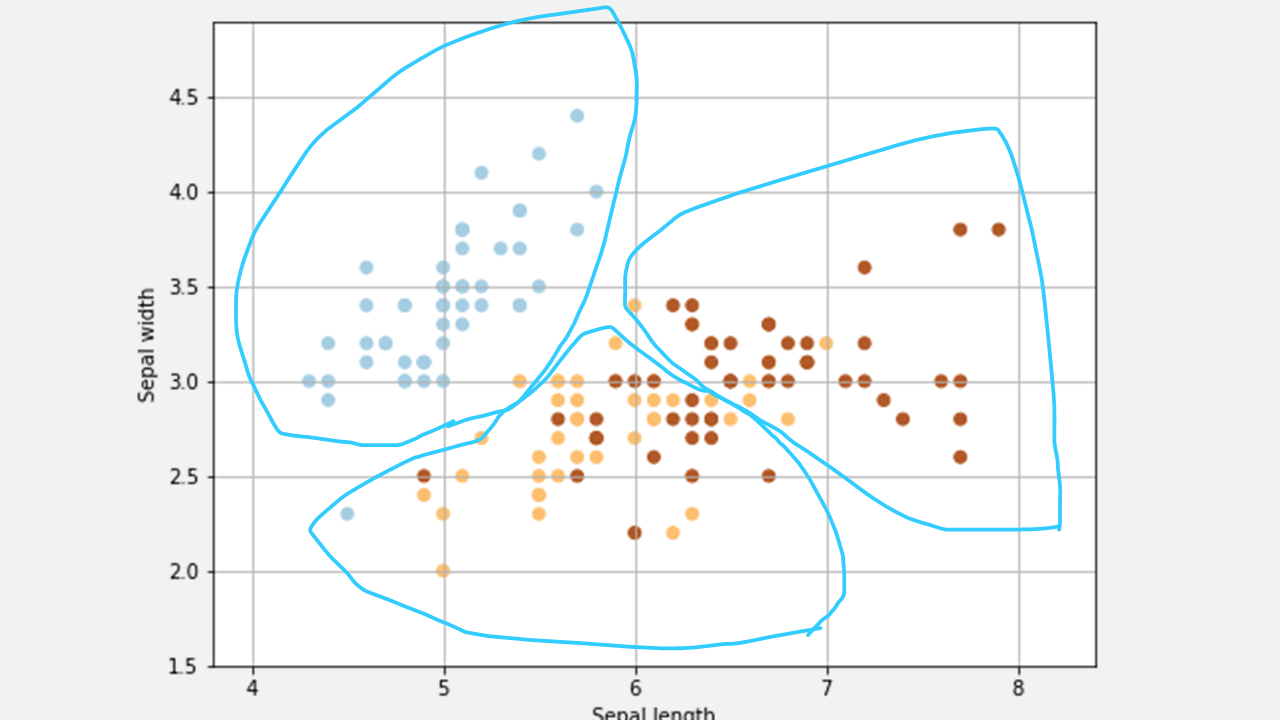
[k-meansのイメージ]
k-meansはクラスタリングの最もシンプルな実装の一つです。meanとは平均を意味し、クラスタを構成するデータの中で平均点をk個用意(最初はランダムな値で平均点を作ります)します。
各データに対して、自分から一番近い平均点を計算します。一番近い平均点のクラスタが各データの所属するクラスタです。
全てのデータのクラスタが決定したら、更にクラスターを構成するデータの中で平均点を作り直します。そうやって平均点を更新したら、またはじめのように各データの一番近い平均点を見つけて所属クラスタを更新します。
このような処理を平均点が更新されなくなるか、ループの上限回数(これは好きに決めてください)に達するまで繰り返します。
あわせて読みたい

k-meansの解説は冒頭のリンク先記事にもありますが、実はk-meansクラスタリングの学習過程を可視化した素晴らしいサイトがあるので、そちらもご覧ください!
k-meansをNumpyで実装
k-meansをPythonとNumpyのみを使って実装しながら、このアルゴリズムがどういう仕組みでクラス分類を行っているのかしっかりと理解して行きましょう!
ライブラリのimport
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import datasets
今回使うライブラリをそれぞれ確認していきましょう。
- Numpy
- 計算を行うメインのライブラリ。
- 様々な数式の操作に対応した便利な関数があるため、基本的にどんな機械学習モデルの実装でも使います。
- Pandas
- データの読み込みや前処理などの機能がまとめられたライブラリ。
- この記事ではデータセットの中身を見るためだけに使っているので、なくてもOKです。
- scikit-learn
- 様々な機械学習モデルの実装が収められたライブラリ。
- データセットをダウンロードして読み込むための関数を使うためにimportしています。
- matplotlib
- Pythonの可視化ライブラリ。
- Pandasの.plotメソッドだけでも可視化はできます。
データの読み込み
k-meansでクラスタリングを行うデータを読み込みます。k-meansが正しく動いているかどうかを確認したいので、きれいにクラスが別れていて使いやすいiris datasetを使います。
iris datasetはUCI Machine Learning Repositoryという有名な機械学習データセットのリポジトリにも収められています。
このページからダウンロードすることも可能ですが、この記事では簡単のためsklearnを使ってデータを読み込んじゃいましょう!
iris = datasets.load_iris() # irisを読み込む関数
df = pd.DataFrame(
iris.data, # データフレームの要素
columns = iris.feature_names # 各列の名前に特徴名を使う
)
df["label"] = iris.target # わかりやすくするためにlabel列を追加、ここにクラス番号を入れておきます。
df.head() # データフレームの先頭5行を表示してみましょう。
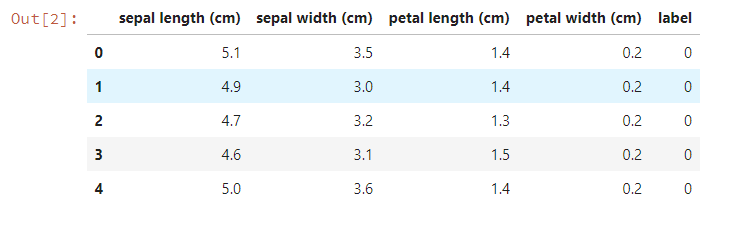
このデータは0~2までの三クラスに対して、それぞれ50個のデータが収められていました。クラスタリングではクラス情報は学習には使いませんが、作成したクラスターとの比較に使います。
今回はDataFrameではなく、もっと単純なデータ構造が使いたいのでnp.arrayに変換しておきます(このときラベルの列は除外します)。
input_data = df.iloc[:,:-1].values # インスタンス属性valuesにアクセスすると、np.arrayが取得できます。
k-meansの実装
それではk-meansの実装を見ていきましょう。
sickit-learnでは、k-meansもクラスとして実装されていました。ですがここではシンプルに実装するために、ただの関数にしています。Numpyの機能を使うことで、非常にスッキリとした実装になりました。
この関数では、引数に以下の3つを受け取ります。
- k
- クラスタ数
- int型
- x
- クラスタリングしたいデータ(行がデータ、列が特徴)
- np.ndarray型
- max_iter
- イテレーションの上限回数
- int型
kmeans関数の出力はデータ数と同じ数のクラスタのインデックス配列(np.ndarray)です。コメントで解説をつけたので読んでみてください!
def kmeans(k, X, max_iter=300):
X_size,n_features = X.shape
# ランダムに重心の初期値を初期化
centroids = X[np.random.choice(X_size,k)]
# 前の重心と比較するために、仮に新しい重心を入れておく配列を用意
new_centroids = np.zeros((k, n_features))
# 各データ所属クラスタ情報を保存する配列を用意
cluster = np.zeros(X_size)
# ループ上限回数まで繰り返し
for epoch in range(max_iter):
# 入力データ全てに対して繰り返し
for i in range(X_size):
# データから各重心までの距離を計算(ルートを取らなくても大小関係は変わらないので省略)
distances = np.sum((centroids - X[i]) ** 2, axis=1)
# データの所属クラスタを距離の一番近い重心を持つものに更新
cluster[i] = np.argsort(distances)[0]
# すべてのクラスタに対して重心を再計算
for j in range(k):
new_centroids[j] = X[cluster==j].mean(axis=0)
# もしも重心が変わっていなかったら終了
if np.sum(new_centroids == centroids) == k:
print("break")
break
centroids = new_centroids
return cluster
計算の高速化やクラスターの重心の初期化方法など、もっと賢い方法はたくさんありますが、ここではシンプルに実装することを目的にしました。Numpyの関数は「これがしたい!」というものに対応した機能が用意されているので、生のPythonで書くよりも宣言的に書くことができて便利です。
結果の確認
結果をチェックしてみましょう。この関数の実行は以下のように行います。
cluster=kmeans(3, input_data)
ここでclusterという変数には、kmeans関数の返り値として各データの所属クラスタのインデックスが入っています。また、kの値は今回、クラスの数と同じ3に設定しました。
ですが実際にはクラスタリングのクラスタ数はクラス数と同じ値にする必要はありません。(※クラスタリングとクラス分類は違うよ! これについては以下をチェック!)
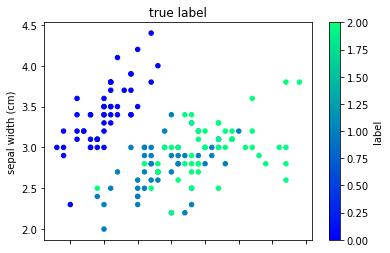
さて、では可視化して実際のクラスタを見てみましょう。
まずは正解ラベルで色付けした可視化です。
df["cluster"] = cluster
df.plot(kind="scatter", x=0,y=1,c="label", cmap="winter") # cmapで散布図の色を変えられます。
plt.title("true label")
次にクラスターで色付けした可視化です。
df.plot(kind="scatter", x=0,y=1,c="cluster", cmap="winter")
plt.title("clustering relust")
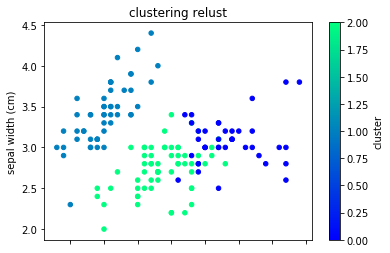
クラスタリングは、クラス分類が目的ではありません。なので見つけることができるデータのまとまりも正解ラベルとは異なったものになっているはずです。
プロットを見てみると、正解ラベルの1と2の境界が曖昧な部分が異なっていますね。この例だとクラスタリングの方がプロット上ではきれいにデータを分けられていることがわかります。
以上がk-meansのPython実装の紹介でした。
まとめ
この記事ではk-meansをPython・Numpyを使って実装しました。
k-meansはクラスタリングの代表的なアルゴリズムです。ここで紹介した実装は非常に簡単ですが、k-meansは非常に奥が深い(詳しく知れば知るほど難しくなっていく)アルゴリズムです。
非常に面白いアルゴリズムだと思うので、この記事をスタートにして勉強してみてはどうでしょうか。




