

こんにちはフクロウです。Pythonのインストラクターをやっています。
ランダムフォレストについて、以前別の記事で使い方の基本を紹介しました。

今回はその続きで、ランダムフォレストを使って回帰分析を行います。系列データの予測を行うのが回帰です。これもランダムフォレストで簡単にできてしまうので、scikit-learnを使って実際の問題に挑戦しましょう。
※この記事のコードはPython 3.6.7、scikit-learn 0.19.2で動作確認しました。
ランダムフォレスト回帰の使い方
目的
ランダムフォレストを使って回帰を行う方法を学びましょう。
回帰の問題に適したデータとして、sklearnにはbostonデータセットが用意されています。bostonデータセットはアメリカのボストン市郊外の地域毎に13種類の特徴と住宅価格のデータが収められています。
ライブラリのimport
まずはライブラリを読み込みましょう。
from sklearn import datasets import numpy as np import matplotlib.pyplot as plt from sklearn.ensemble import RandomForestRegressor as RFR from sklearn.model_selection import train_test_split, GridSearchCV
4行目のimportがここで使うランダムフォレストのクラスです。
scikit-learn(以下sklearn)には
- RandomForestClassifier
クラス分類用 - RandomForestRegressor
回帰分析用(今回はこっち)
の二種類のランダムフォレストクラスがあるので、目的にあったものを使いましょう。
データの読み込み
boston = datasets.load_boston() train_data_bs, test_data_bs, train_labels_bs, test_labels_bs = train_test_split(boston.data, boston.target, test_size=0.2)
データの読み込みはdatasets.load_bostonで行います。train_test_split関数はデータを教師データとテストデータに分割してくれる関数でしたね。
ランダムフォレストモデルの学習
まずはパラメタサーチをしないで回帰を行ってみます。sklearnでのランダムフォレストの使用は非常に簡単です。
- sklearnの機械学習モデル(ランダムフォレスト)のインスタンスを作成する
- 教師データと教師ラベルを使い、fitメソッドでモデルを学習
rg = RFR(n_jobs=-1, random_state=2525) rg.fit(train_data_bs,train_labels_bs)
[出力結果]
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=-1,
oob_score=False, random_state=2525, verbose=0, warm_start=False)
これで学習が終わりました。
学習済みモデルの評価
学習の評価方法も、クラス分類のときと同じメソッドを使いましょう。
predicted_labels_bs = rg.predict(test_data_bs) rg.score(test_data_bs, test_labels_bs) # 結果:0.8511986928634983
なかなかいい結果が出たように見えますね。今回の結果は折れ線グラフで可視化するべきものではないですが、わかりやすく結果を確認するためにやってみましょう。
plt.figure(figsize=(20,10)) plt.plot(test_labels_bs,label="True") plt.plot(predicted_labels_bs, label="predicted") plt.legend()
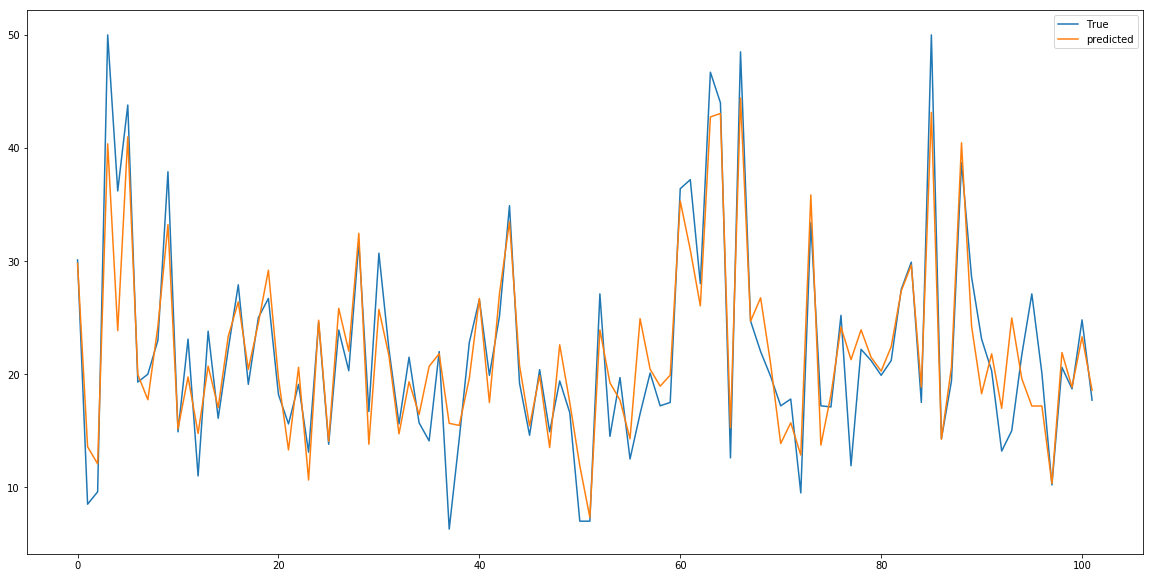
多少ズレがありますが、予測ができていることがわかると思います。
ハイパーパラメータをチューニング
さて、クラス分類のときと同じく、パラメータサーチを行いましょう。
search_params = {
'n_estimators' : [5, 10, 20, 30, 50, 100, 300],
'max_features' : [i for i in range(1,train_data_bs.shape[1])],
'random_state' : [2525],
'n_jobs' : [1],
'min_samples_split' : [3, 5, 10, 15, 20, 25, 30, 40, 50, 100],
'max_depth' : [3, 5, 10, 15, 20, 25, 30, 40, 50, 100]
}
gsr = GridSearchCV(
RFR(),
search_params,
cv = 3,
n_jobs = -1,
verbose=True
)
gsr.fit(train_data_bs, train_labels_bs)
使い方は基本的に同じです。ただ探索するパラメータの名前や範囲などには気をつけてください。
[出力結果]
Fitting 3 folds for each of 8400 candidates, totalling 25200 fits
[Parallel(n_jobs=-1)]: Done 18 tasks | elapsed: 0.2s
[Parallel(n_jobs=-1)]: Done 1520 tasks | elapsed: 9.4s
[Parallel(n_jobs=-1)]: Done 2904 tasks | elapsed: 18.0s
[Parallel(n_jobs=-1)]: Done 4304 tasks | elapsed: 27.0s
[Parallel(n_jobs=-1)]: Done 6104 tasks | elapsed: 39.0s
[Parallel(n_jobs=-1)]: Done 8304 tasks | elapsed: 54.4s
[Parallel(n_jobs=-1)]: Done 10904 tasks | elapsed: 1.2min
[Parallel(n_jobs=-1)]: Done 13904 tasks | elapsed: 1.6min
[Parallel(n_jobs=-1)]: Done 17304 tasks | elapsed: 2.0min
[Parallel(n_jobs=-1)]: Done 21104 tasks | elapsed: 2.4min
[Parallel(n_jobs=-1)]: Done 25200 out of 25200 | elapsed: 2.9min finished
GridSearchCV(cv=3, error_score='raise',
estimator=RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0, warm_start=False),
fit_params={}, iid=True, n_jobs=-1,
param_grid={'n_estimators': [5, 10, 20, 30, 50, 100, 300], 'max_features': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], 'random_state': [2525], 'n_jobs': [1], 'min_samples_split': [3, 5, 10, 15, 20, 25, 30, 40, 50, 100], 'max_depth': [3, 5, 10, 15, 20, 25, 30, 40, 50, 100]},
pre_dispatch='2*n_jobs', refit=True, scoring=None, verbose=True)
探索結果を見てみましょう。まずは最も良かったモデルです。
print(gsr.best_estimator_)
[出力結果]
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=15,
max_features=10, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=3, min_weight_fraction_leaf=0.0,
n_estimators=50, n_jobs=1, oob_score=False, random_state=2525,
verbose=0, warm_start=False)
次に最も良かったモデルの評価です。
gsr.best_estimator_.score(test_data_bs, test_labels_bs) # 0.8692014722718724
性能が上がっていますね。予測ラベルと正解ラベルのグラフは以下の通りです。
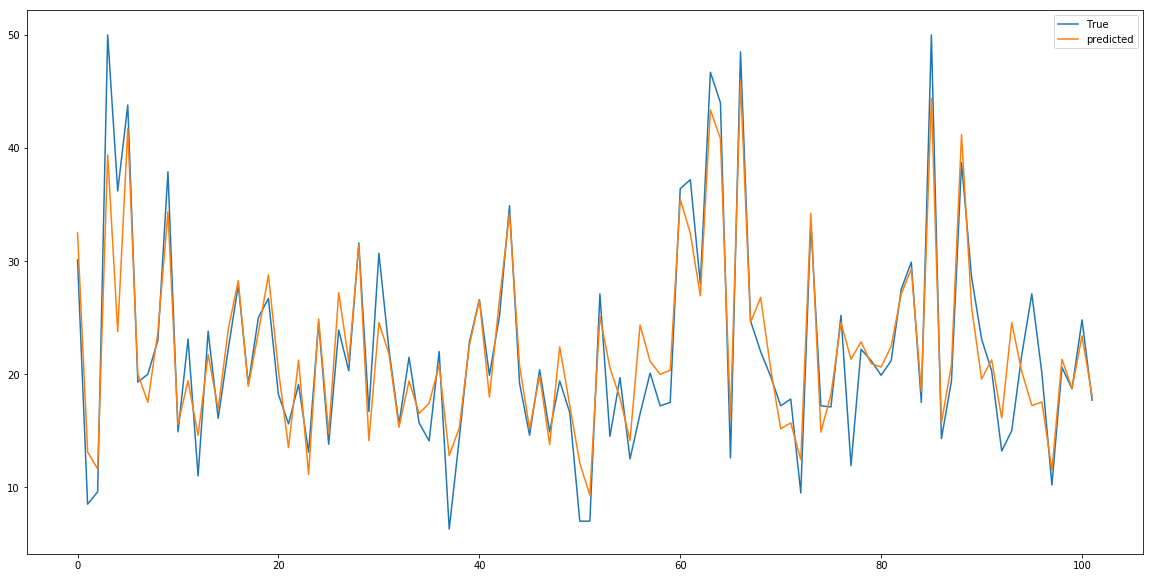
まとめ
この記事ではランダムフォレストを使った回帰分析についてまとめました。
でもこの記事を読んでいるうちに「scikit-learnじゃなくて自分でランダムフォレストを実装したい」とか「もっとどうやって回帰しているのか知りたい」と思った方、いるんじゃないでしょうか。
そんな方は侍のマンツーマンレッスンにチャレンジしてみてください。より詳しい解説をインストラクターから受けられますよ。




